1일차
빅데이터라면 보통 1테라.
데이터는 사용하면 할 수록 쌓인다.
1) 정보전자화 : 아날로그에서 디지털로 이동
- 아날로그 시대의 사고를 중심으로 설계
2) 디지털화 : 디지털 데이터를 사용하여 작업방식을 간소화하는 것
전자화된 정보를 사용하여 간단하고 효율적으로 만드는 과정
- 제조 솔루션
3) 디지털전환 : 비즈니스 수행방식을 바꾸어 놓거나, 어떤 경우 완전히 새로운 종류의 비즈니스 창출
기술의 잠재력을 이해하는것
보유 기술을 사용하여 어떤 것을 할 수 있는지 이해하는 것이 중요
- 고객을 위한 사업
ICT기술을 이요하여 제조기업의 변화
Smart Factory
ICT기술을 이용하여 제조기업의 디지털화 (자동화와 정보화)
1) 자동화(OT;Operration Technology) : 데이터를 수집
데이터수집 : PLC, HMI, SCADA, DCS
현장인프라자동화(HW, AT(Automation Technology)) : 설비자동화, 컨베이어, 로봇
2) 정보화(IT;Information Technology) : 데이터를 활용
지능형시스템 : (최적화, 예측, 원인분석) AI, 빅데이터, CPS, Digital Twin, AR/VR...
제조시스템 : (통제,운영, 관리) ERP, MES, PLM/POM, CMMS, QMS, WMS,
목적(Factory) -> 기술(Smart)
기업이윤+고객만족 ICT기술
자동화
정보화
지능화
내부역량
과제1
제조현장의 데이터
4M(Man, Machine, Material, Method)
실적, 불량, 설비 상태, Alarm
공정조건(압력, 속도, 온도 등) - 제조사양
품질규격(치수, 중량, 특성치 등) - 제품 사양
과제2 : 제조 현장의 정확한 데이터 수집에 중점
데이터 Log 기록 및 저장 중요하다.
시(時)계열 데이터가 유용하다.(시계열 : 시간계열데이터)
검사자동화 및 검사 데이터 수집
과제3 : 제조 데이터의 분석 역량 강화 및 활용에 집중
p29
top10
지능형 솔루션 적용분야
전문가 시스템 : 문제해결능력을 가질 수 잇도록 만들어진 시스템
데이터 마이닝 : 잠재적으로 유용할 것 같은 정보를 추출하는 체계적인 과정
패턴 인식 : 데이터에 있는 패턴이나 규칙성, 기계적인 장치가 어떠한 대상을 인식하는 문제를 다루는 인공지능의 한 분야
자연어 처리 : 사람이 사용하는 일반 언어로 작성된 문서를 처리하고 이해하는 분야
10. 아래 거래 데이터에서 연관규칙 '기저귀->맥주'의 향상도는? 37회 49번
| 거래번호 | 구매상품 |
| 1 | 기저귀, 맥주, 빵 |
| 2 | 기저귀, 맥주 |
| 3 | 기저귀, 빵, 음료수 |
| 4 | 빵, 음료수, 커피 |


RPA(Robotic Process Automation)란? RPA(Robotic Process Automation)는 디지털 시스템 및 소프트웨어와 사람 사이의 상호 작용을 에뮬레이션하는 소프트웨어 로봇을 쉽게 빌드, 구현, 및 관리할 수 있도록 해주는 소프트웨어 기술입니다.
https://www.youtube.com/live/a6RdFTdgoWI?si=l5So92KsegXrg7Nu
P36 역할참조
데이터 엔지니어 : 코딩 잘 하는 사람
데이터 에널리스트 :
분석도구, 대시보드 등 시각화 도구 활용
데이터 사이언티스트 : 보다 깊이 있는 분석 기법적용, (쉐프)
데이터 리서처
데이터 기획자
시티즌 데이터 사이언티스트 : 데이터 관련 부서가 아니라 다른 실무 부서(혹은 취미)에서 데이터를 특히 많이 다루는 사람을 칭함.
P37 표 삽입
"인공지능을 만든다는 것은 지능적 행동을 하도록 알고리즘을 만든다."
P46
소프트웨어>인공지능?머신러닝(기계학습)>딥러닝
지도학습 : 답이 있다.
비지도학습 : 답이 없을 수 있다.
설명가능한 AI
1일차 오후
P67
프로젝트 수행 절차
72
DDA - 기술적 데이터 분석
EDA - 탐색적 데이터 분석
CDA - 확증적 데이터 분석
PDA - 예측적 데이터 분석
대상 -> 데이터 -> 분석 -> 시각화
-> 기술통계 -> 추론(가설/검정)
https://www.kamp-ai.kr/
KAMP, 인공지능제조플랫폼
스마트 대한민국 구현의 허브!제조 AI 강국으로의 도약 KAMP가 함께합니다.
www.kamp-ai.kr
제조데이터분석체험

비정형 데이터도 훌륭한 데이터가 될 수 있다.
빅데이터(Bigdata) -> 인사이트(Insight) -> 가치(Value)
88,89
데이터애널리틱스(아래로 갈 수록 난이도가 높다.)
서술분석,(Descriptive) : 현황, MES, ERP / 월별 불량현황
전단분석(Diagnostic) : 통계, 시각화 / 특정 공정 생산성이 낮은 이유
예측분석(Predictive) : 머신러닝(기계학습) / 설비의 고장 날 시점 예측
처방분석(Prescriptive) : 최적화 / 양품 생산을 위한 공정 최적화
MES(제조 실행 시스템)는 전체 생산 수명주기를 모니터링, 추적, 문서화, 제어해 제조 프로세스를 최적화하도록 설계된 소프트웨어입니다. MES는 품질 관리를 향상하고 가동 시간을 늘리는 동시에 재고 및 비용을 줄여줍니다.
90
비즈니스 관점의 데이터 분석 단계
미래학?을 공부해 볼까???
91
빅데이터 분석 수명 주기의 9단계 !!!
93
성공적인 기획의 3요소 : 임펙트, 데이터, 분석
최종가치의 정의 : 의사결정자(현업)
94
의사결정자는 빅데이터 분석이 무엇인지, 인사이트는 어떻게 생겼는지,
그 실행과정에서 어떤 두려움을 만나게 될지 직접 체험해봐야 한다.
"최소한 이러지는 말자"
98
시각화도구 Python
대시보드 : Tableau, Power BI, Google Analysis,
https://www.tableau.com/ko-kr
Tableau: 비즈니스 인텔리전스 및 분석 소프트웨어
Tableau는 비즈니스 인텔리전스를 위한 시각적 분석 소프트웨어입니다. Tableau를 통해 어떤 데이터든 보고 이해할 수 있습니다.
www.tableau.com
102
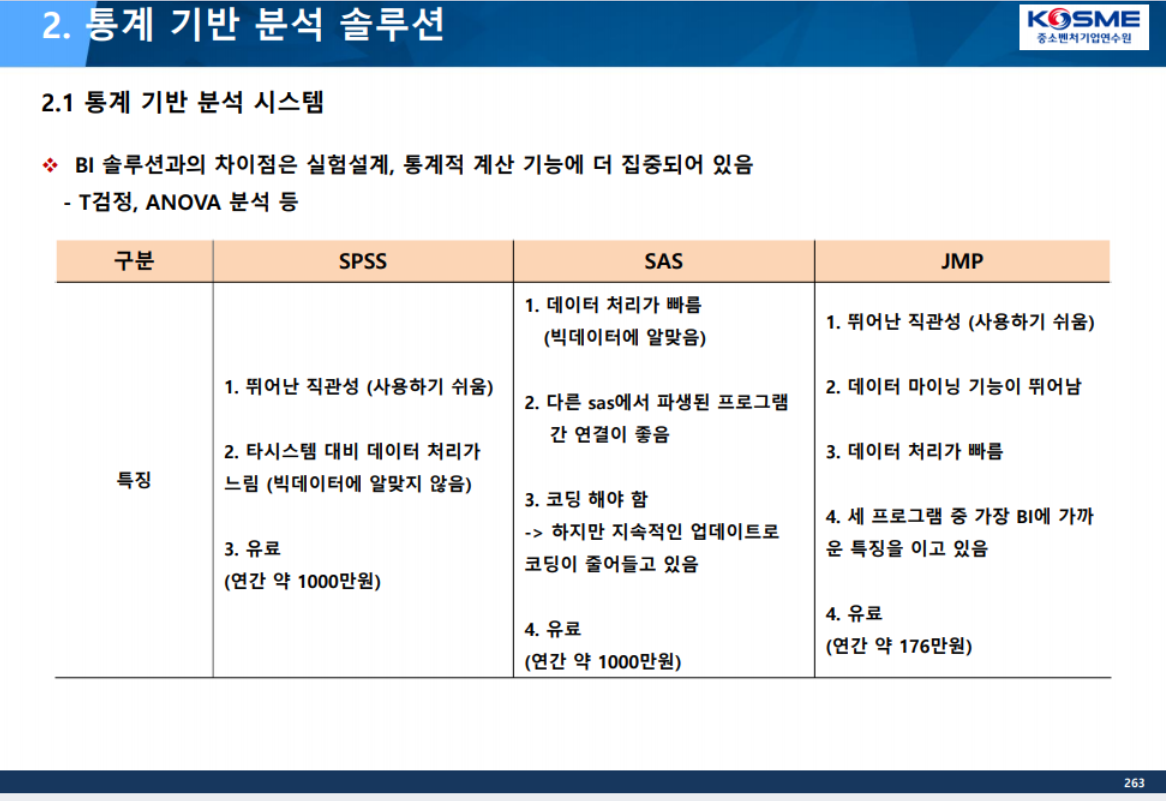
인공지능(머신러닝) : orange3,
번석 -> 통계 : SAS, JMP...
103
웹크롤링
크롤링(crawling) 은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
105
데이터 애널리스트 : 통계학 기초 수준 알아두면 좋다
데이터 사이언티스트, 데이터 리서치 : 수학, 통계학, 정보이론 필수
데이터 엔지니어 : 프로그래밍 집중
시티즌 데이터 사이언티스트 : 통계학 기초 수준, 데이터분석 소프트웨어 활용 역량 집중
108
지도학습 - 머신러닝 : 답이 있다.
고양이, 개 사진
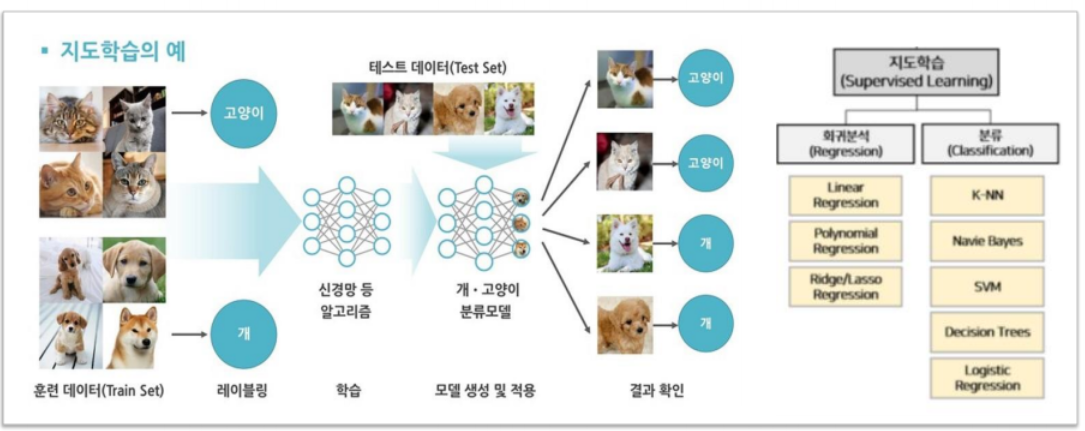
108
과적합
과소적합
과대적합
Dataset 정의 : 학습용 데이터셋, 테스트용 데이터셋, 검증용 데이터 셋 분류,
비율은 비슷하게 설정하는게 좋다.
111
오분류표
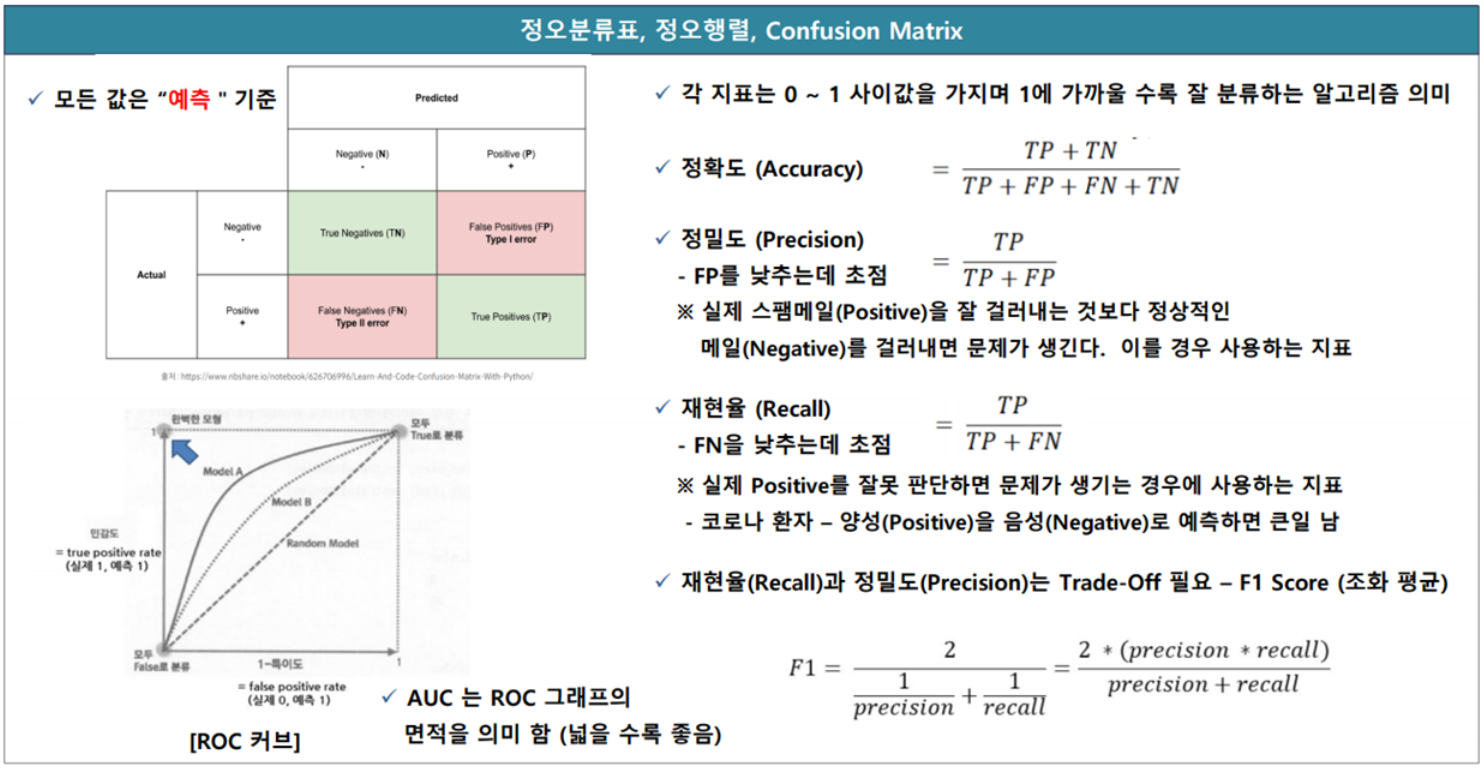
| 예측값 TRUE | 예측값 FALSE | TOTAL | |
| 실제값 TRUE | 30(TP) | 70(FP) | 100 |
| 실제값 FALSE | 60(FN) | 40(TN) | 100 |
| TOTAL | 90 | 110 | 200 |

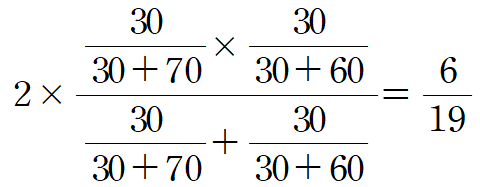
114
의사결정나무
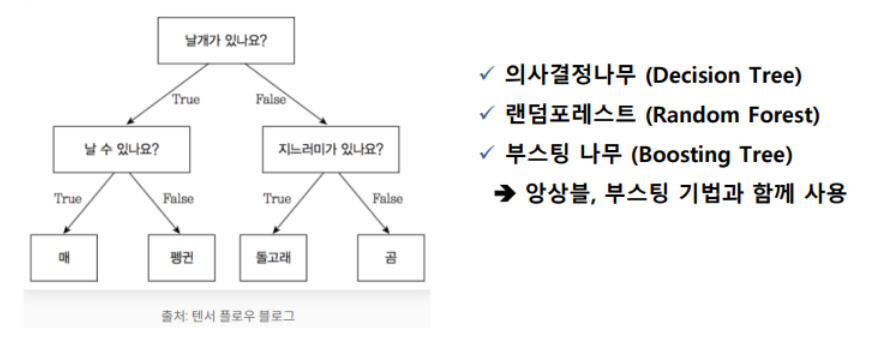
모든 머신러닝 툴은 딥러닝기능은 빠져있다. GPU를 사용해야하기 때문에.
129
워드클라우드
https://art.wordrow.kr/
친절한AI
https://youtu.be/FwQyXG07Rhw?si=0G9qVVj_DZZ9SplQ
엘리샘(오랜지)
https://youtu.be/o9Hkopf9KCU?si=gs3W0qiEV7ParNF_
이수완컴퓨터
https://youtu.be/epN6vh-XFfE?si=h23-Ki53lkV0duAz
135
통계학
데이터의 분석목적 : 데이터요약, 대상설명, 데이터 예측
145
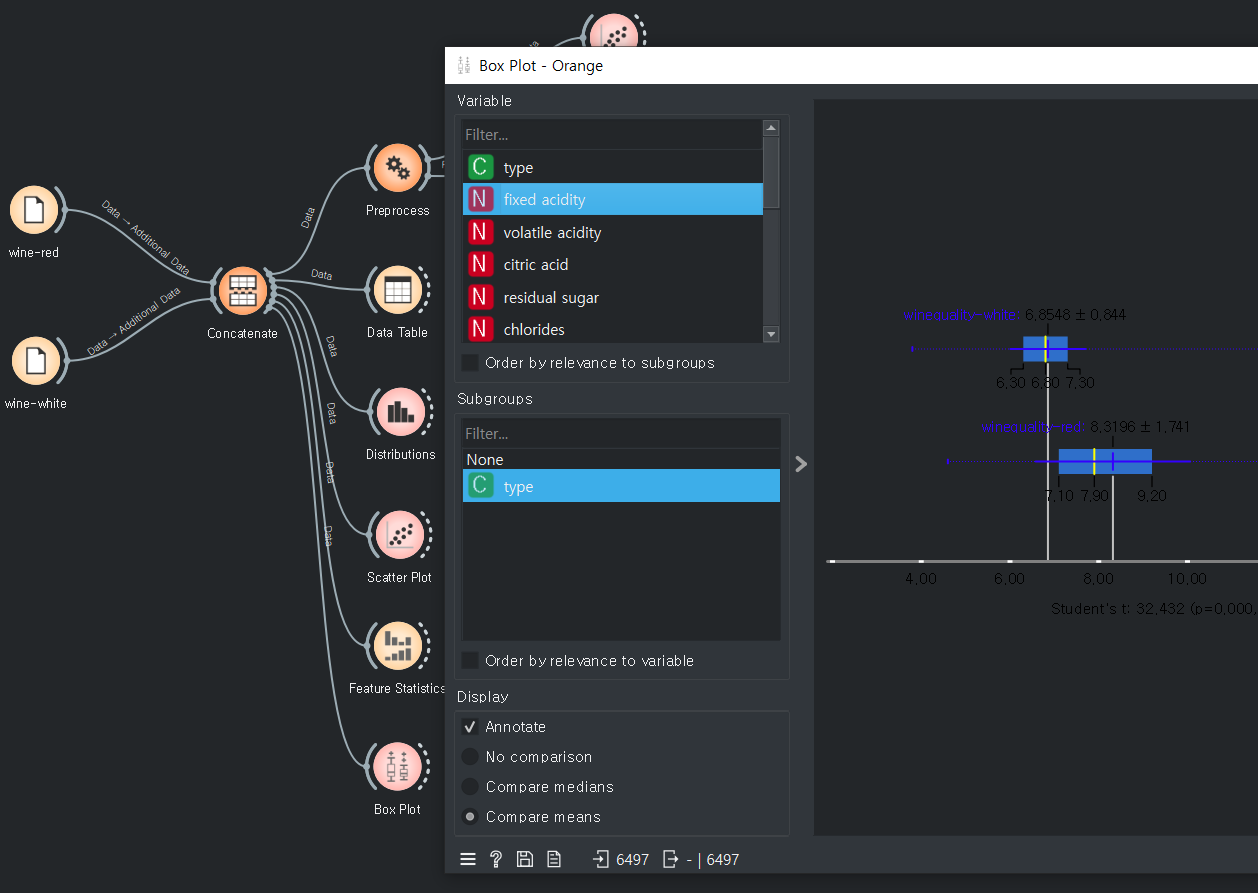
박스플롯
149
이산확률분포
연속확률분포
면적
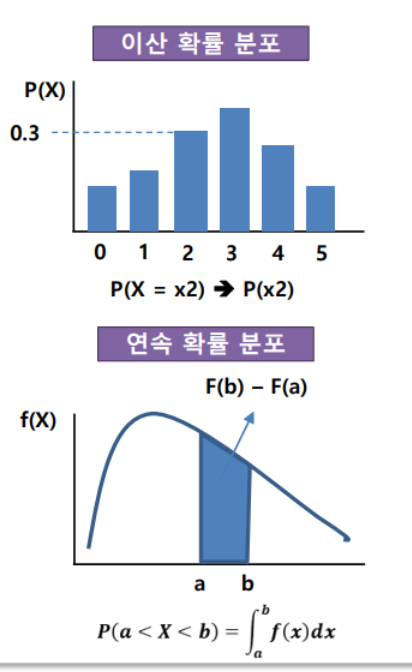
세상은 다양한 변수로 이루어져 있죠. 어떤 변수는 뚜렷한 값을 가지고, 어떤 변수는 끊임없이 변화하죠. 이를 통계학에서는 이산 변수와 연속 변수로 구분합니다. 마치 뚜렷한 색깔의 블록과 부드러운 물감으로 이루어진 그림처럼 말이죠.
1. 이산 분포: 뚜렷한 블록으로 이루어진 세상
- 상상해보세요. 주사위를 굴리는 모습을. 나올 수 있는 눈은 1, 2, 3, 4, 5, 6 뿐입니다. 마치 서로 다른 색깔의 6개 블록처럼 말이죠. 이처럼 이산 변수는 제한된 개수의 뚜렷한 값을 가질 수 있습니다.
- 예시: 동전 앞뒷면, 주사위 눈, 시험 점수, 결혼 여부, 사망 여부
2. 연속 분포: 부드러운 물감으로 이루어진 세상
- 이제는 키를 재는 모습을 상상해보세요. 키는 1.7m, 1.71m, 1.72m... 이렇게 무한히 세분화될 수 있습니다. 마치 부드러운 물감처럼 말이죠. 이처럼 연속 변수는 무한히 많은 값을 가질 수 있으며, 특정 값의 확률은 0입니다.
- 예시: 키, 몸무게, 온도, 소득, 학점
- 특징이산 분포연속 분포
값 뚜렷한 개수 (예: 1, 2, 3) 무한히 많은 값 (예: 1.7, 1.71, 1.72) 확률 특정 값의 확률 계산 가능 (예: 1 나올 확률은 1/6) 특정 값의 확률은 0 (예: 키가 정확히 170cm일 확률은 0) 표현 확률 질량 함수 (PMF) 사용 확률 밀도 함수 (PDF) 사용 그래프 막대 그래프 곡선 그래프
171
T-TEST(검정)

산점도(散點圖,scatter plot, scatterplot, scatter graph, scatter chart, scattergram, scatter diagram)는 데카르트 좌표계(도표)를 이용해 좌표상의 점(點)들을 표시함으로써 두 개 변수 간의 관계를 나타내는 그래프 방법이다 ...
산점도
https://newsjel.ly/archives/newsjelly/15193
산점도 차트 읽기, 알고 보면 어렵지 않아요! - 뉴스젤리 : 데이터 시각화 전문 기업
산점도의 개념과 해석 방법, 그리고 산점도를 응용한 시각화 사례까지 함께 알아봐요!
newsjel.ly

산점도가 사진과 같이 나왔다면 중요한 변수는 X1, X2 중에 무엇일까?
X2 변수가 훨씬 중요한 변수이다.
X2값에 의해 결과값이 크게 달라질 수 있다.
디지털트윈 소프트웨어 UNITY
https://unity.com/kr/solutions/digital-twin-applications-and-use-cases
상위 10가지 디지털 트윈 사용 사례
다양한 산업 분야에서 디지털 트윈을 사용하는 방법에 대해 알아보고 이 기술이 현실에 미치는 효과를 보여 주는 혁신적인 활용 사례를 확인해 보세요.
unity.com
260
BI솔루션 제품 특징
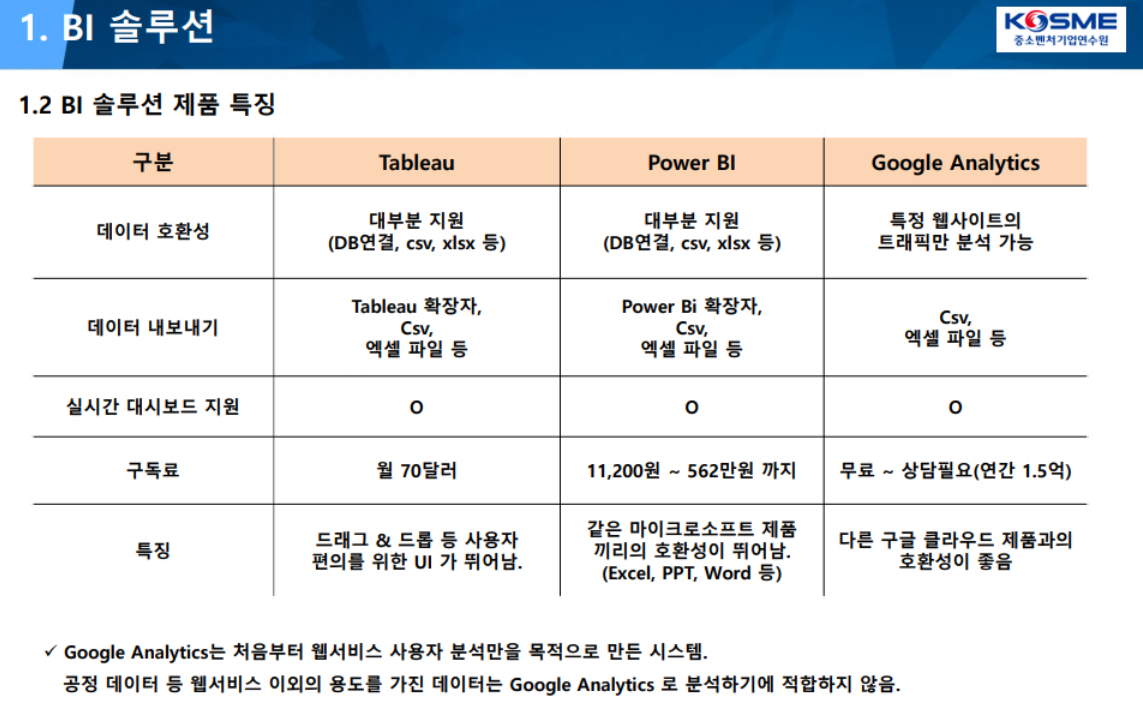
263

2일차
https://orangedatamining.com/docs/
Orange Data Mining
Orange Data Mining Toolbox
orangedatamining.com
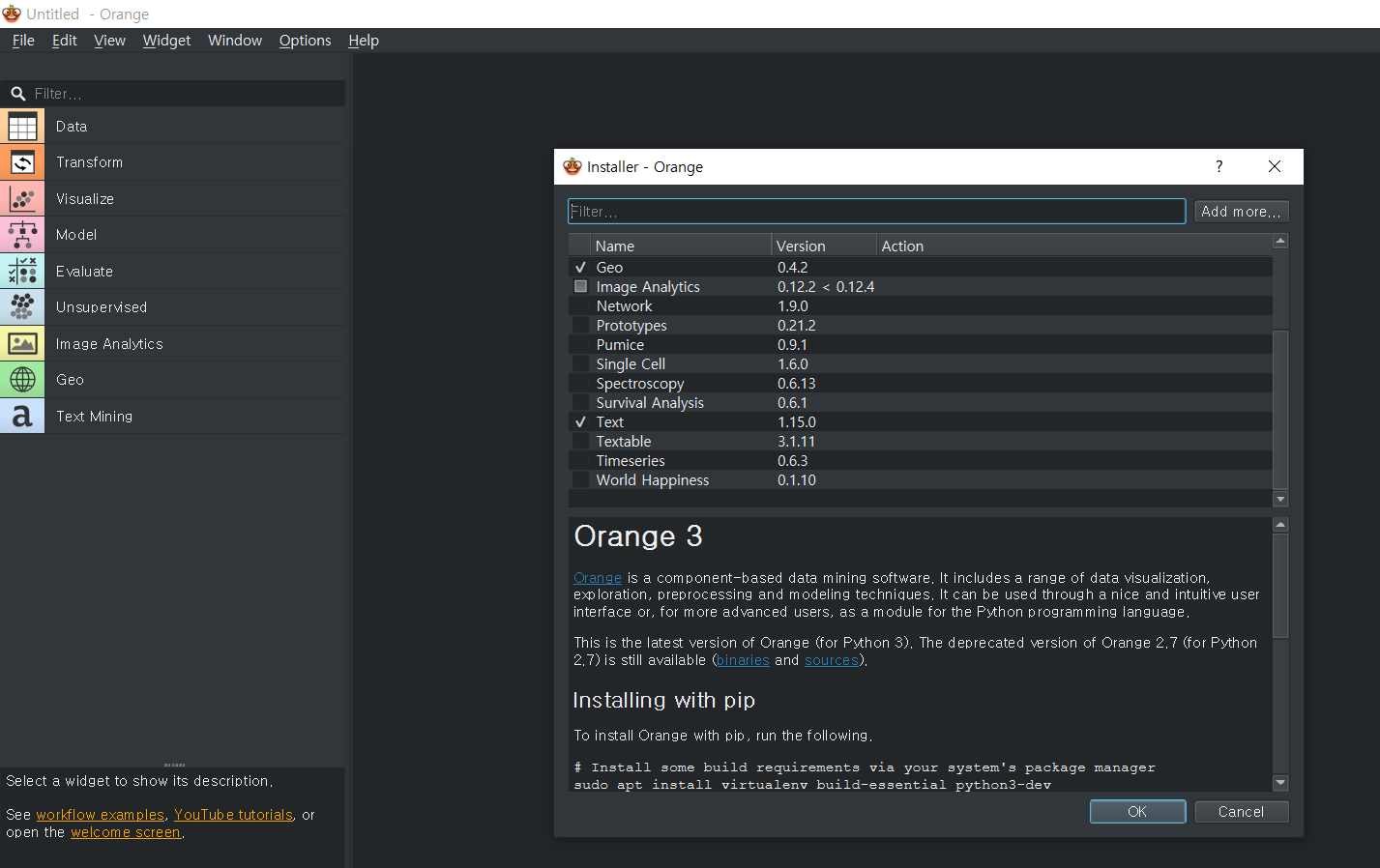
geo, text, ImageAnalysis 추가 add-on
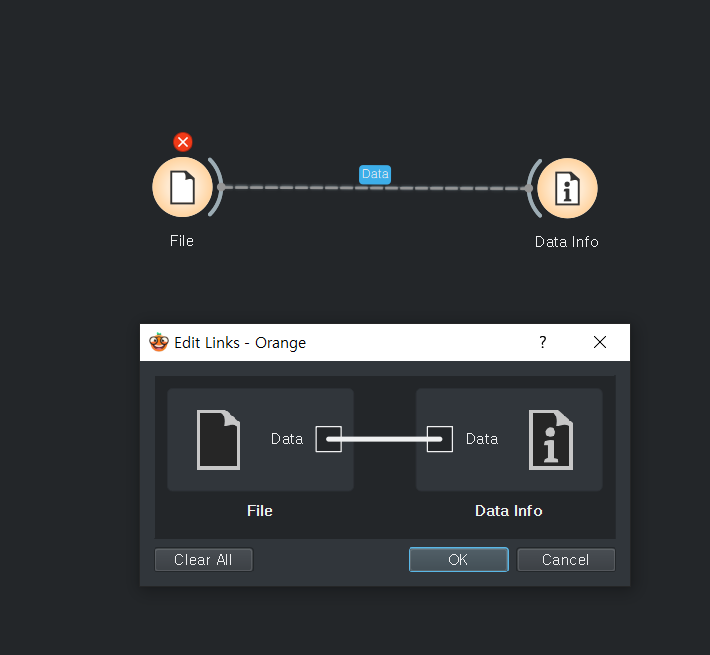
링크 삭제는 del 을 누르면 된다.
데이터 삽입
불러온 데이터의 전처리 과정
시각화 출력물
지도학습 머신러닝
비지도학습 머신러닝
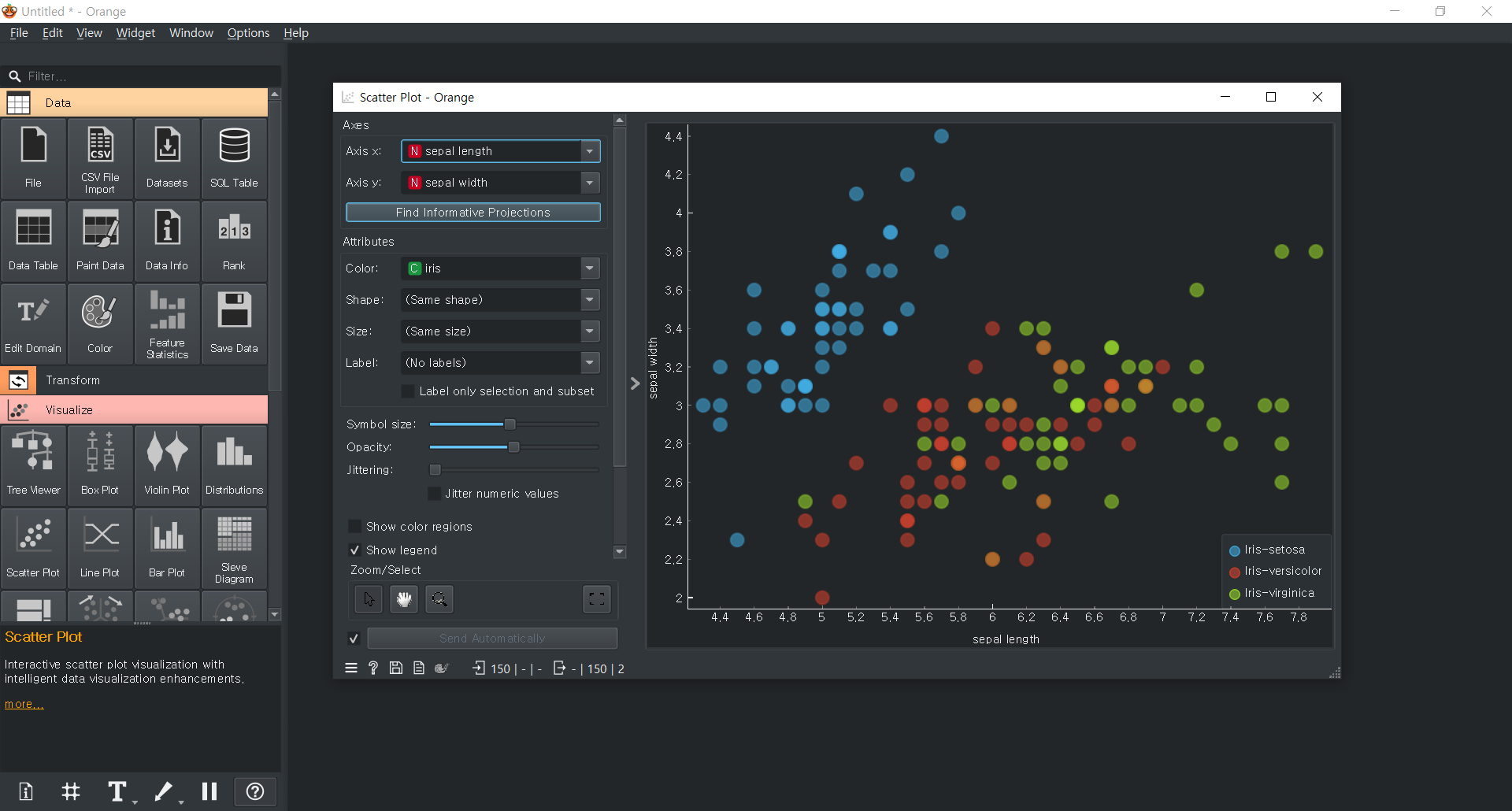
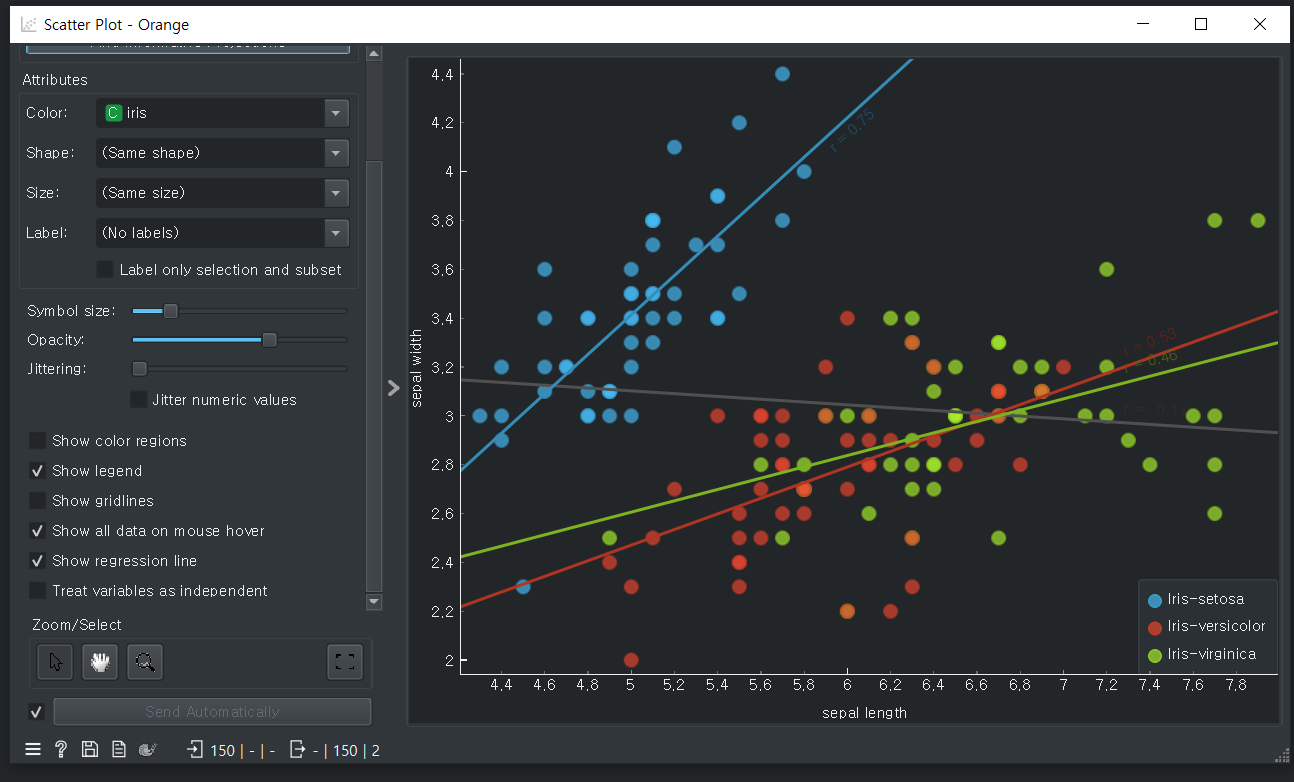
회귀분석라인 보이기 (regression line)
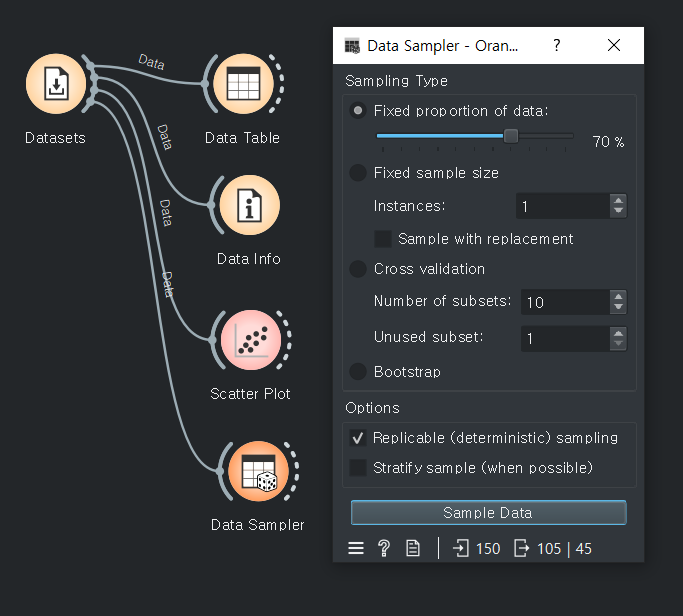
70%만 학습시키기105/150 =70%
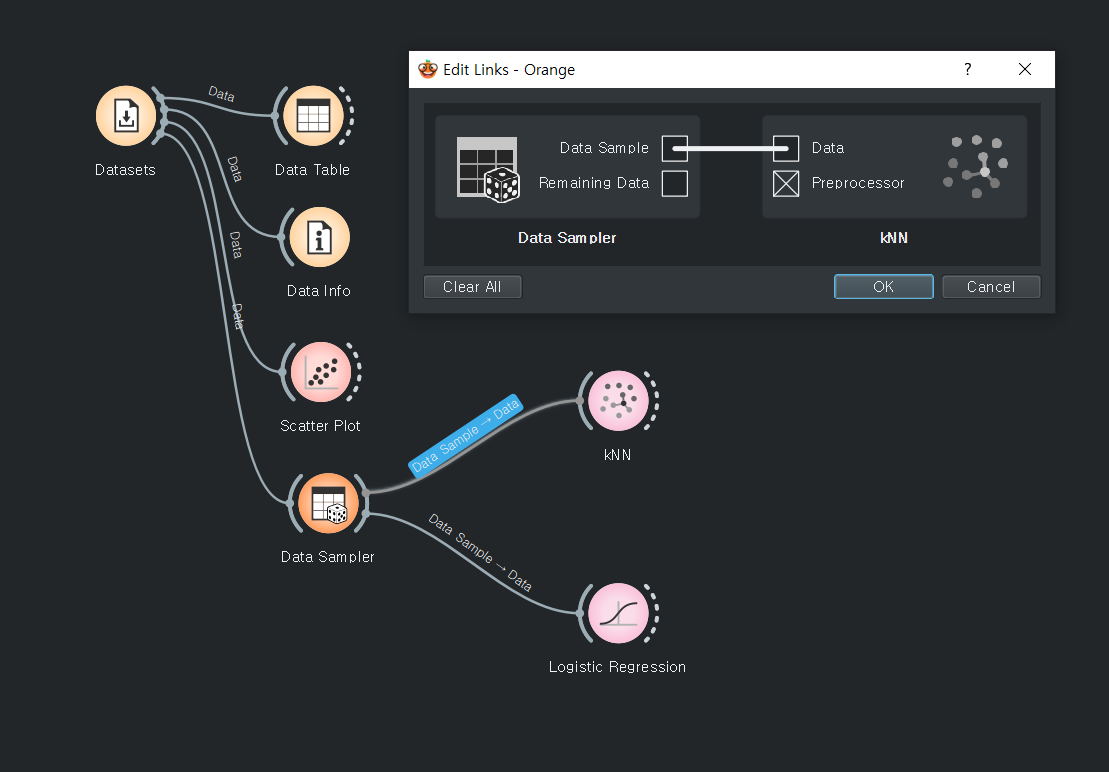
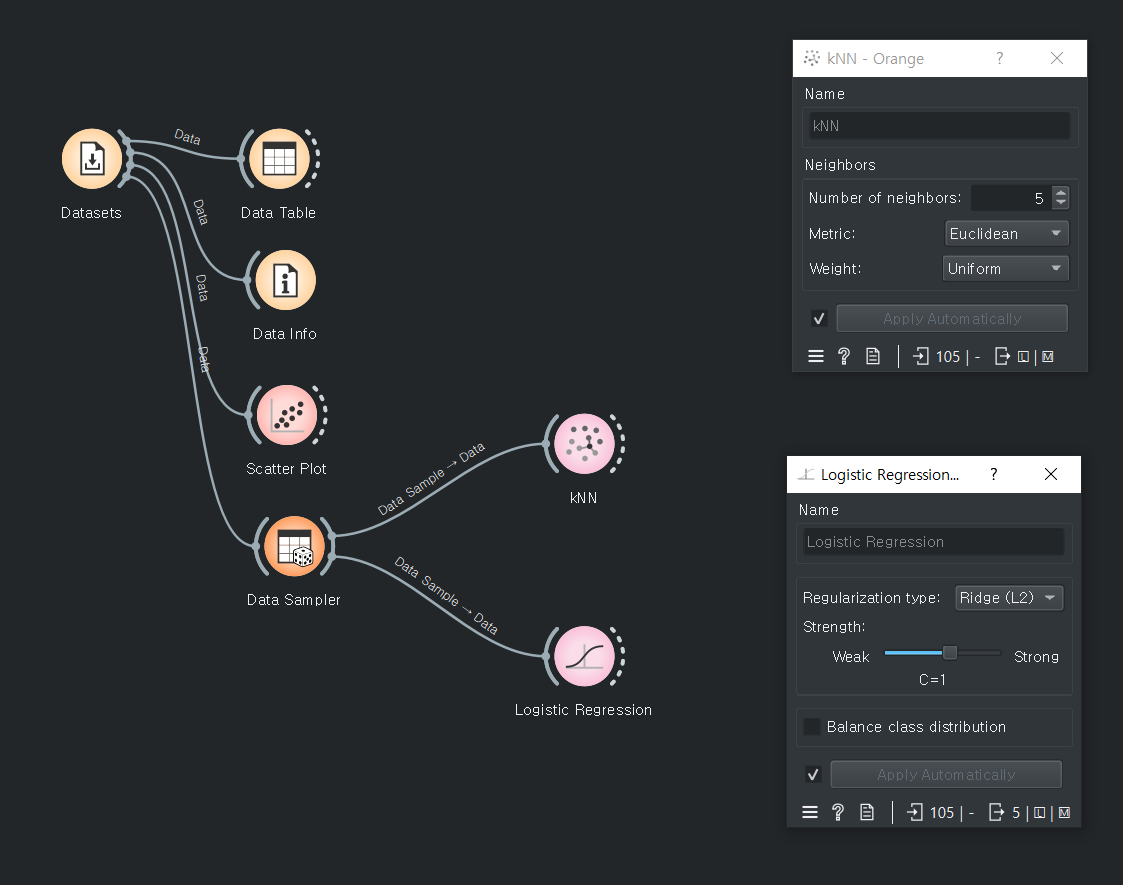
여러개의 속성 창을 띄워 설정값을 수정할 수 있다.
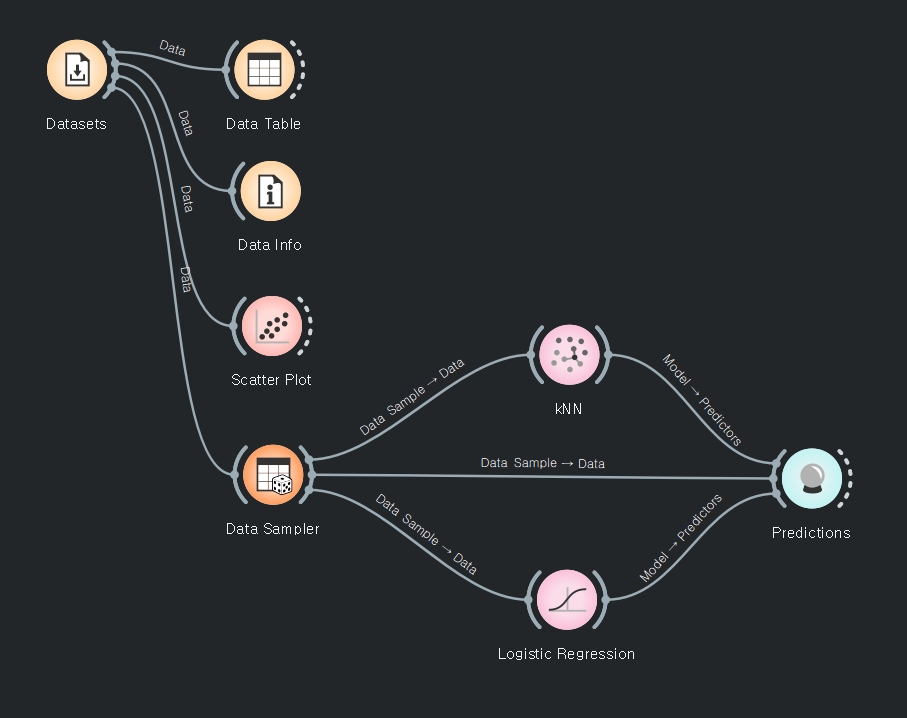
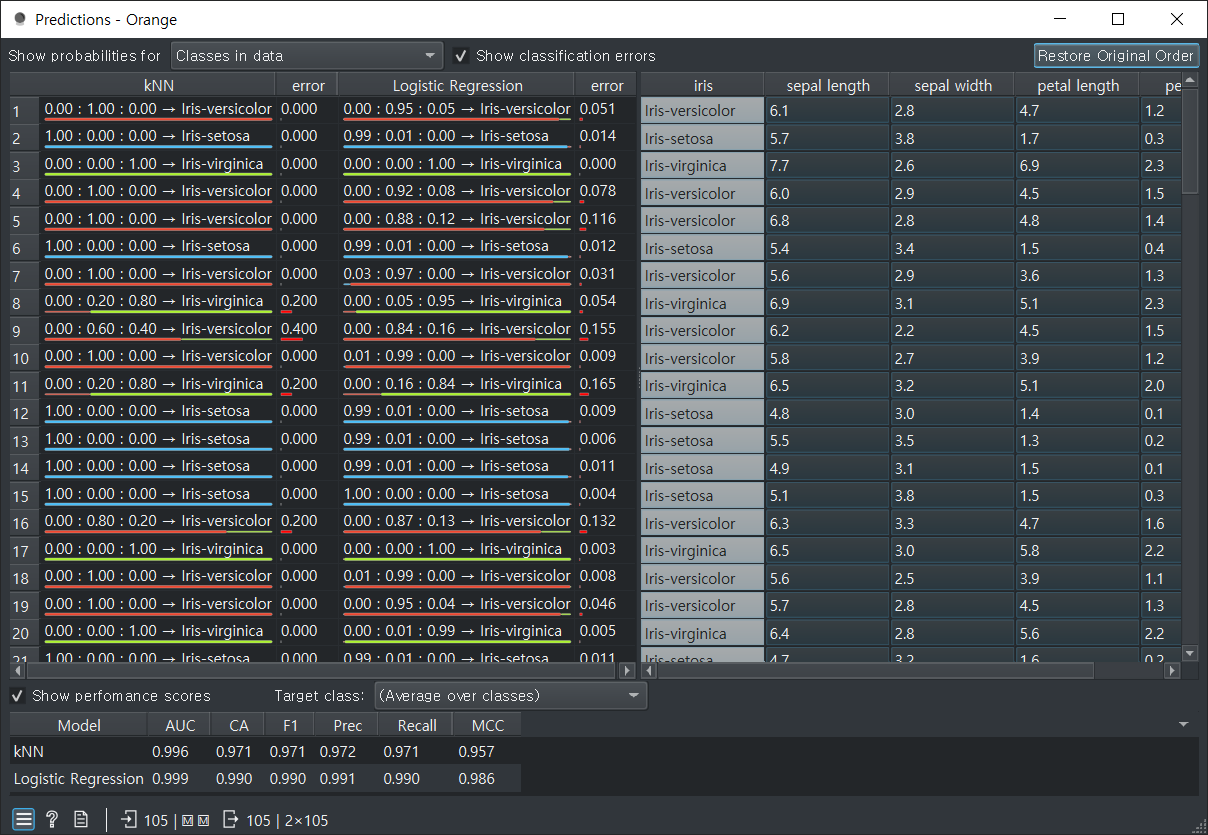
품종에 대한 색상별로 결과가 나온다.
error 0.00 : 오차범위 -> 100% 확신하는 데이터
kNN : 형상의 비숫한 것을 비교한다.
Logistic Regression : 수학적으로 비교한다.
Predictions : 예측
k-최근접 이웃 알고리즘 (K-Nearest Neighbors)이란?
k-최근접 이웃(KNN) 알고리즘은 머신러닝 분야에서 많이 쓰이는 분류 및 회귀 기법 중 하나입니다.
간단히 말하면, kNN 알고리즘은 새로운 데이터를 분류하거나 값을 예측할 때 가장 가까운 과거 데이터 몇 개 (k개)를 이용합니다.
https://github.com/ProfSynapse/Synapse_CoR
GitHub - ProfSynapse/Synapse_CoR
Contribute to ProfSynapse/Synapse_CoR development by creating an account on GitHub.
github.com
titanic
파일을 불러오면 자동 적용된다. apply버튼은 비활성화된 상태로 보여진다.
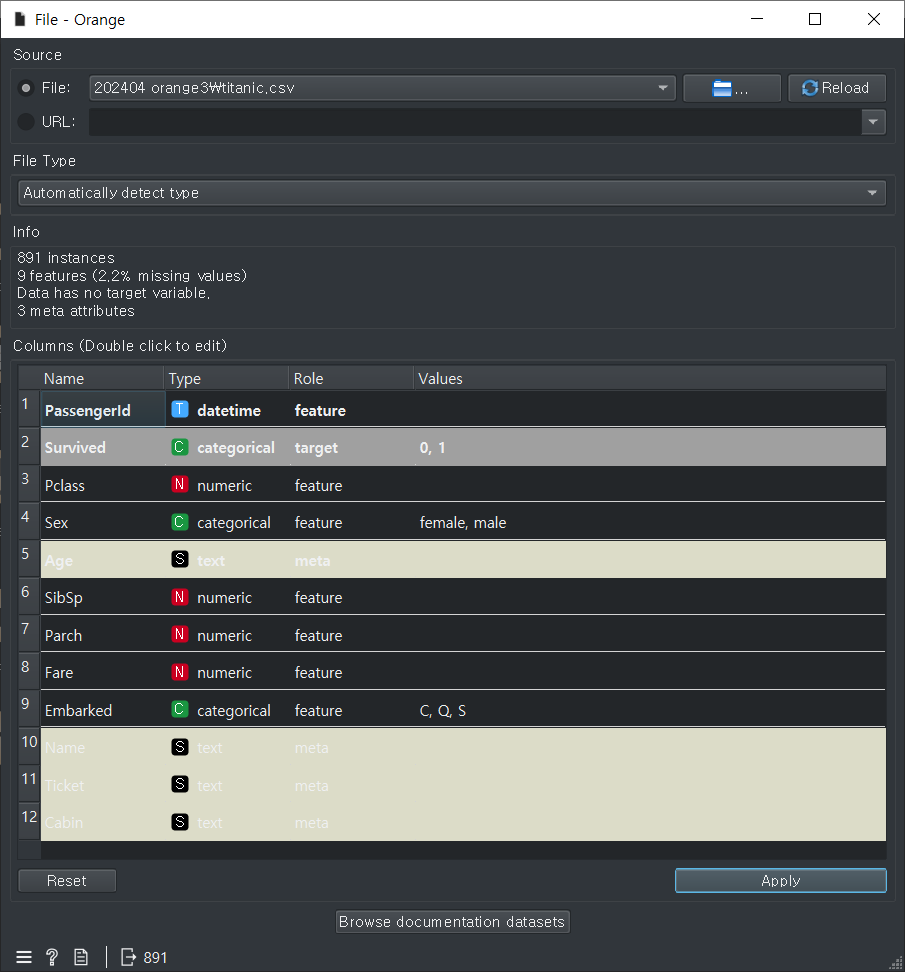
생존자를 알기위해 target으로 변경한다.
다른 예제(mearge long1 long2, sex)
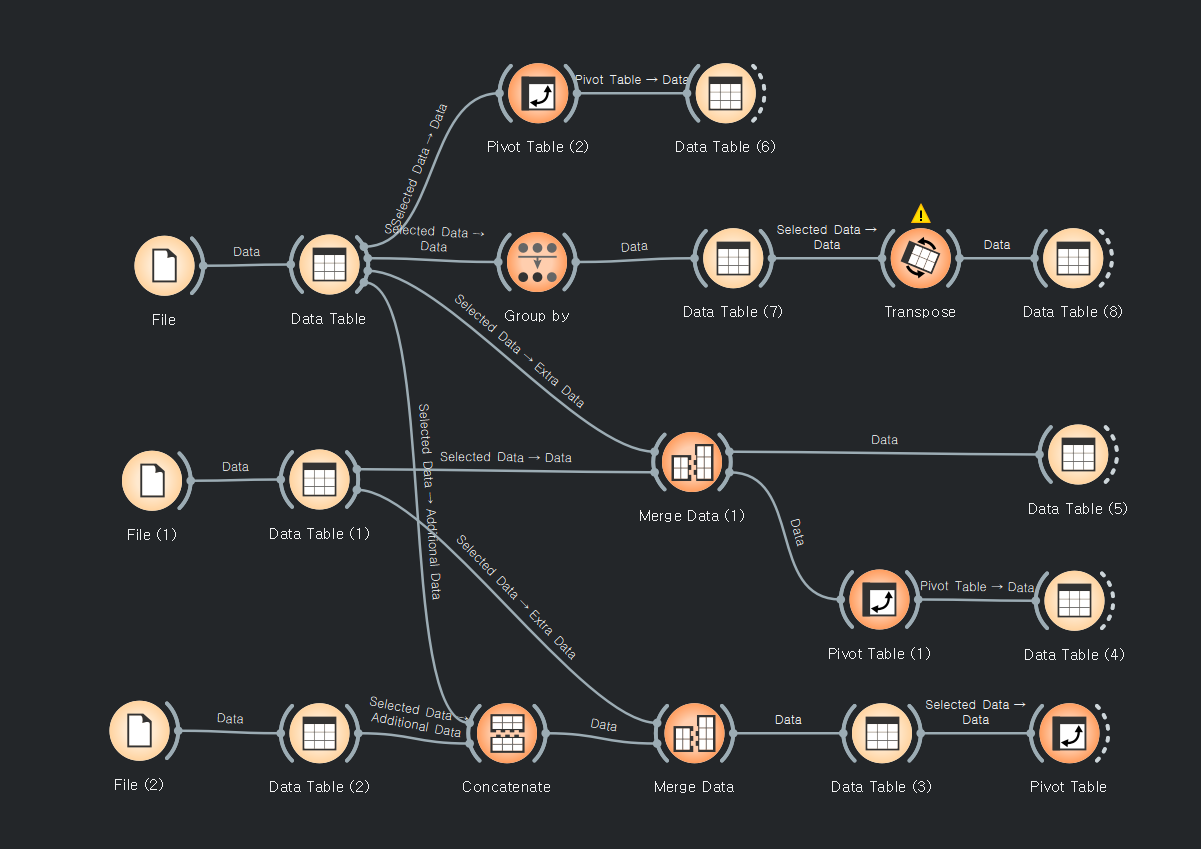
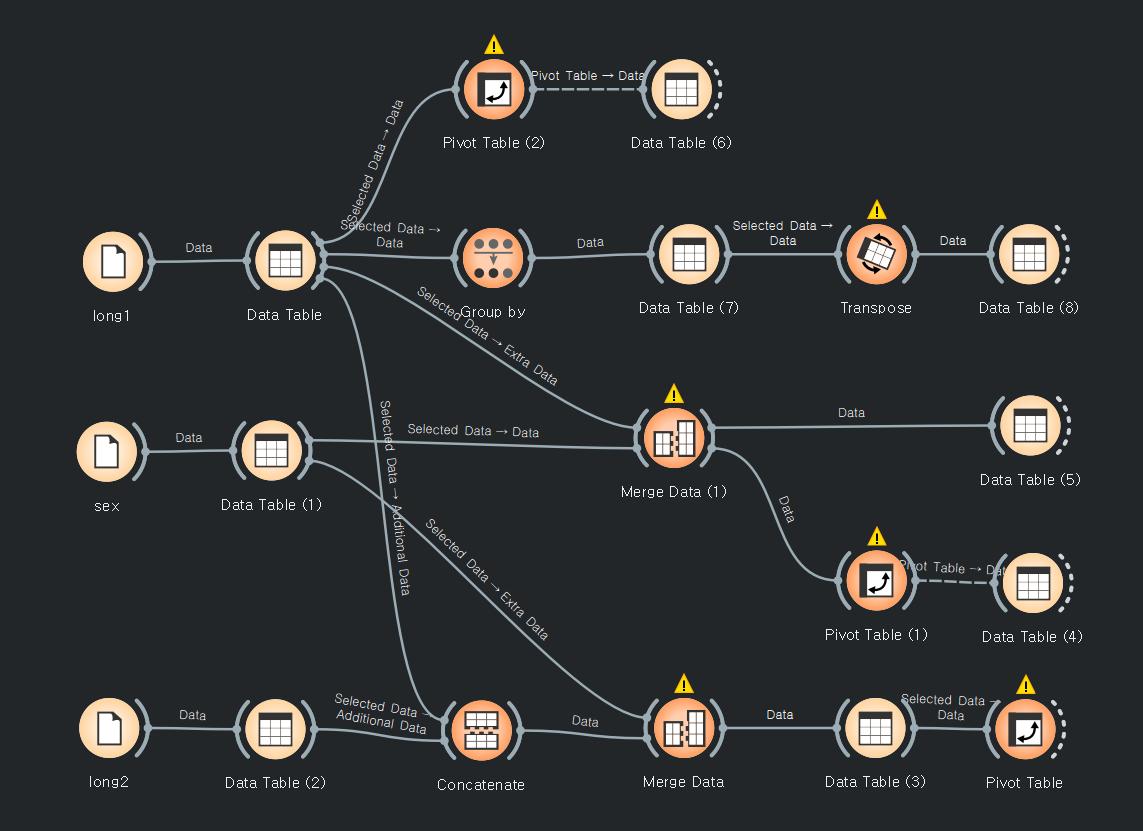
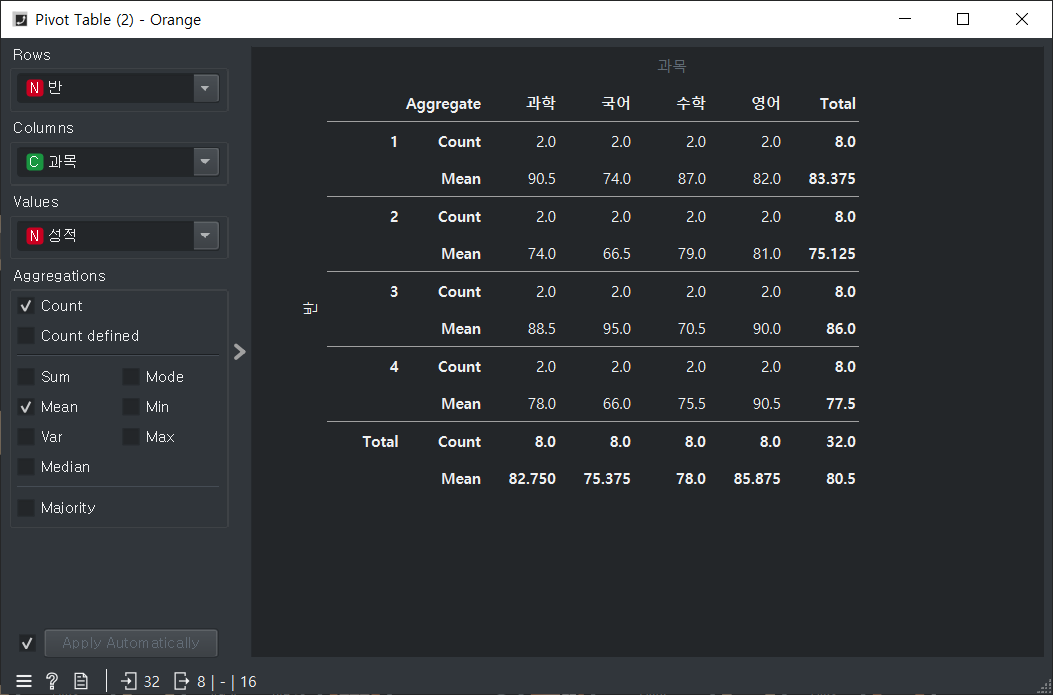
long1의 피벗테이블
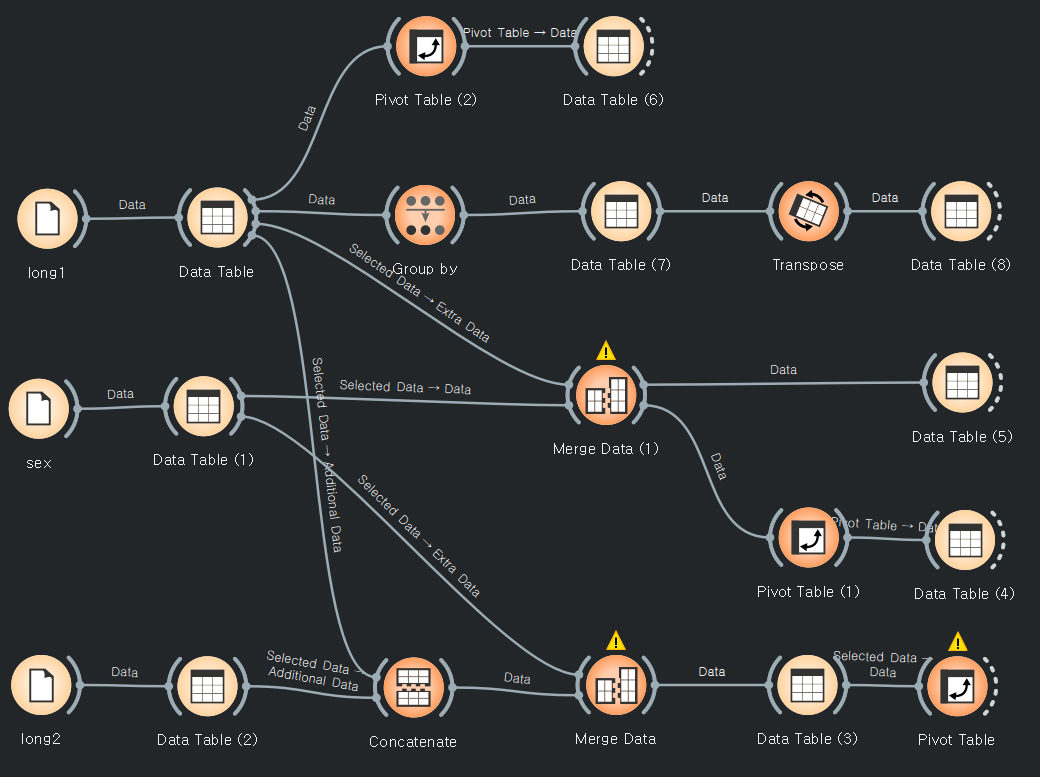
링크값이 선택된 데이터인지, 전체데이터인지 잘 봐야 된다.
피벗테이블과 트랜스포스는 비숫한 기능을 가지고 있다. 디테일은 당연히 다르겠지???
 |
트랜스포스 -> |  |
데이터가 몇 개 없을 때는 엑셀의 수식이 편하다.
빅데이터라면 오랜지가 편하다.
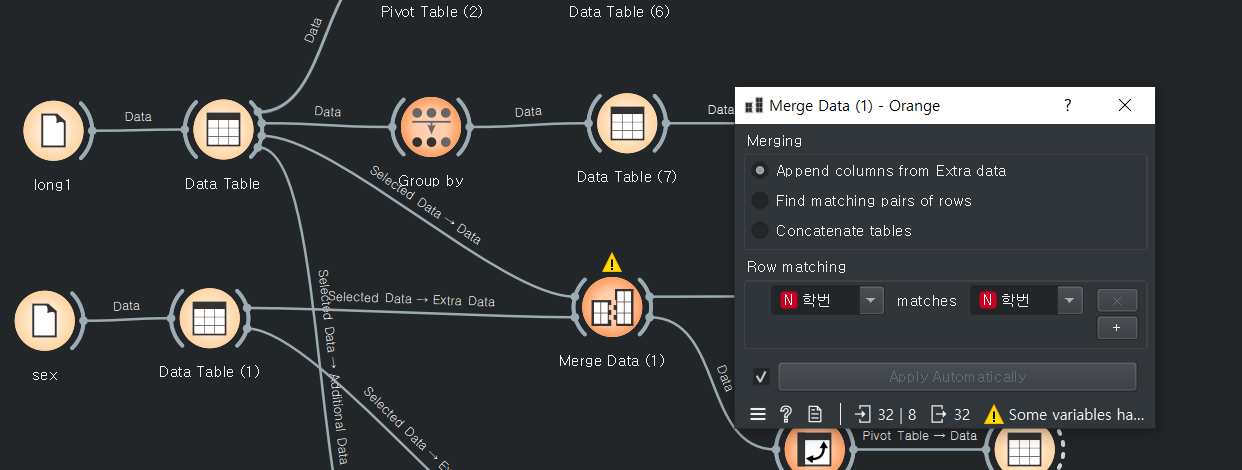
학번을 기준으로 두개의 파일을 marge했다.
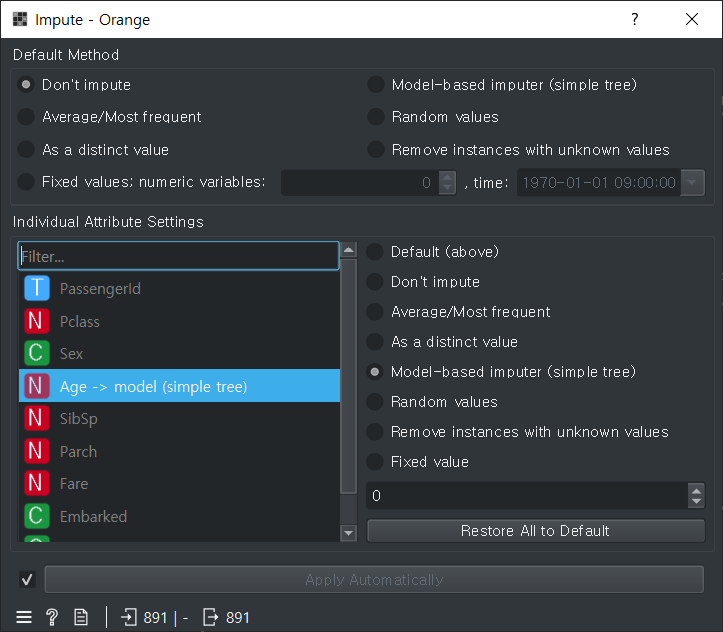
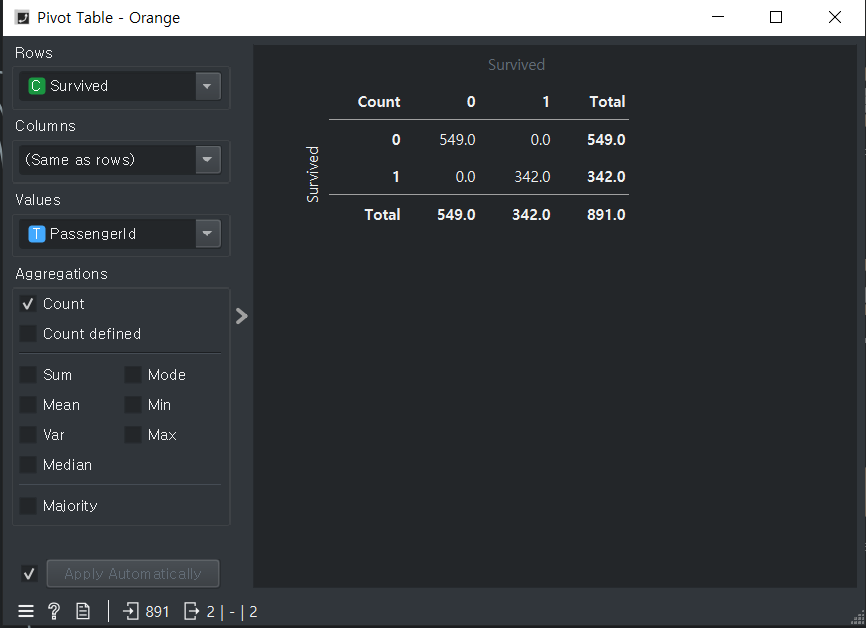
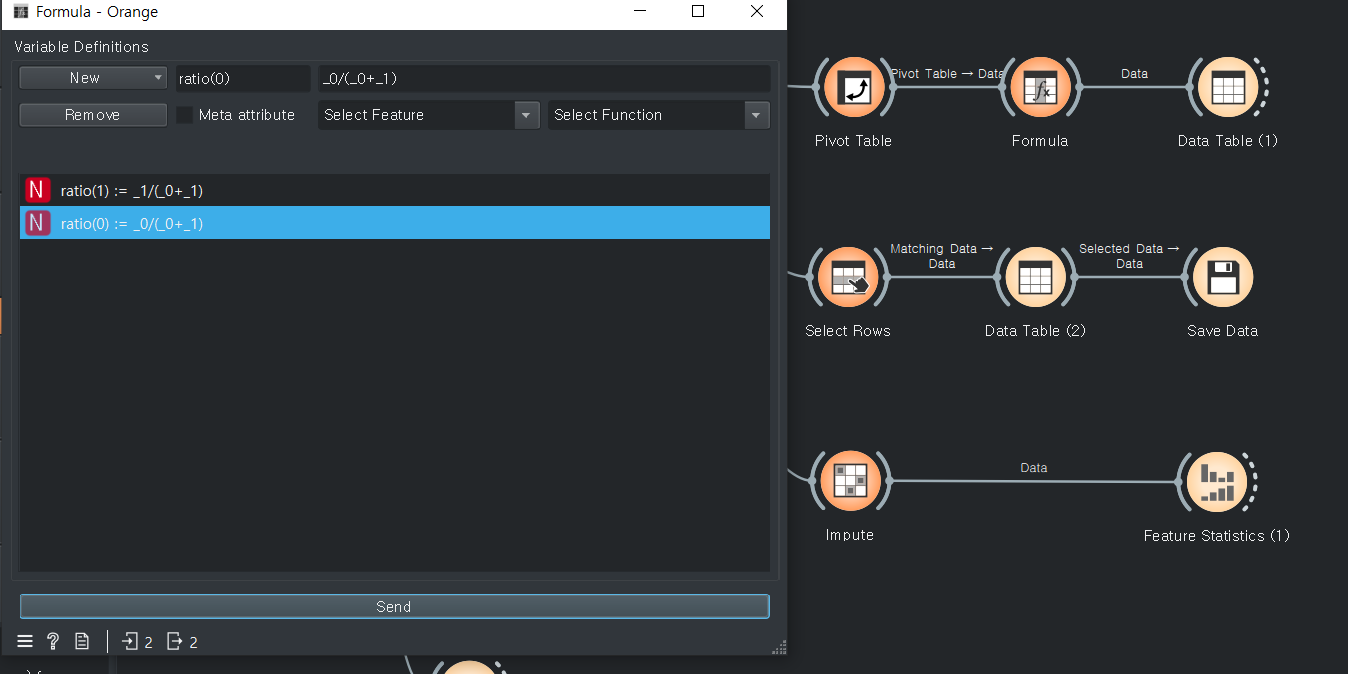
Stastistics : 통계
2일차 오후
전처리과정에서 튀는 값은 삭제한다.
기본데이터양이 적으면 데이터를 늘려준다.
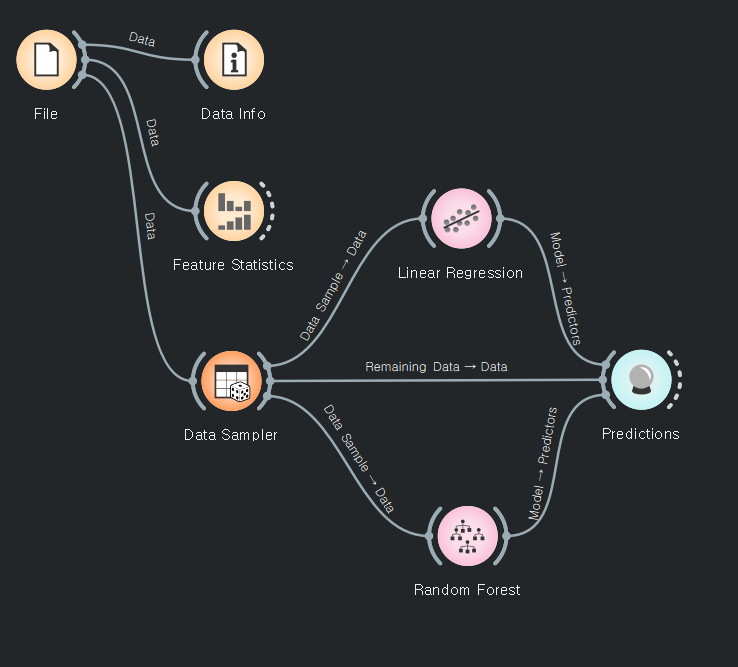
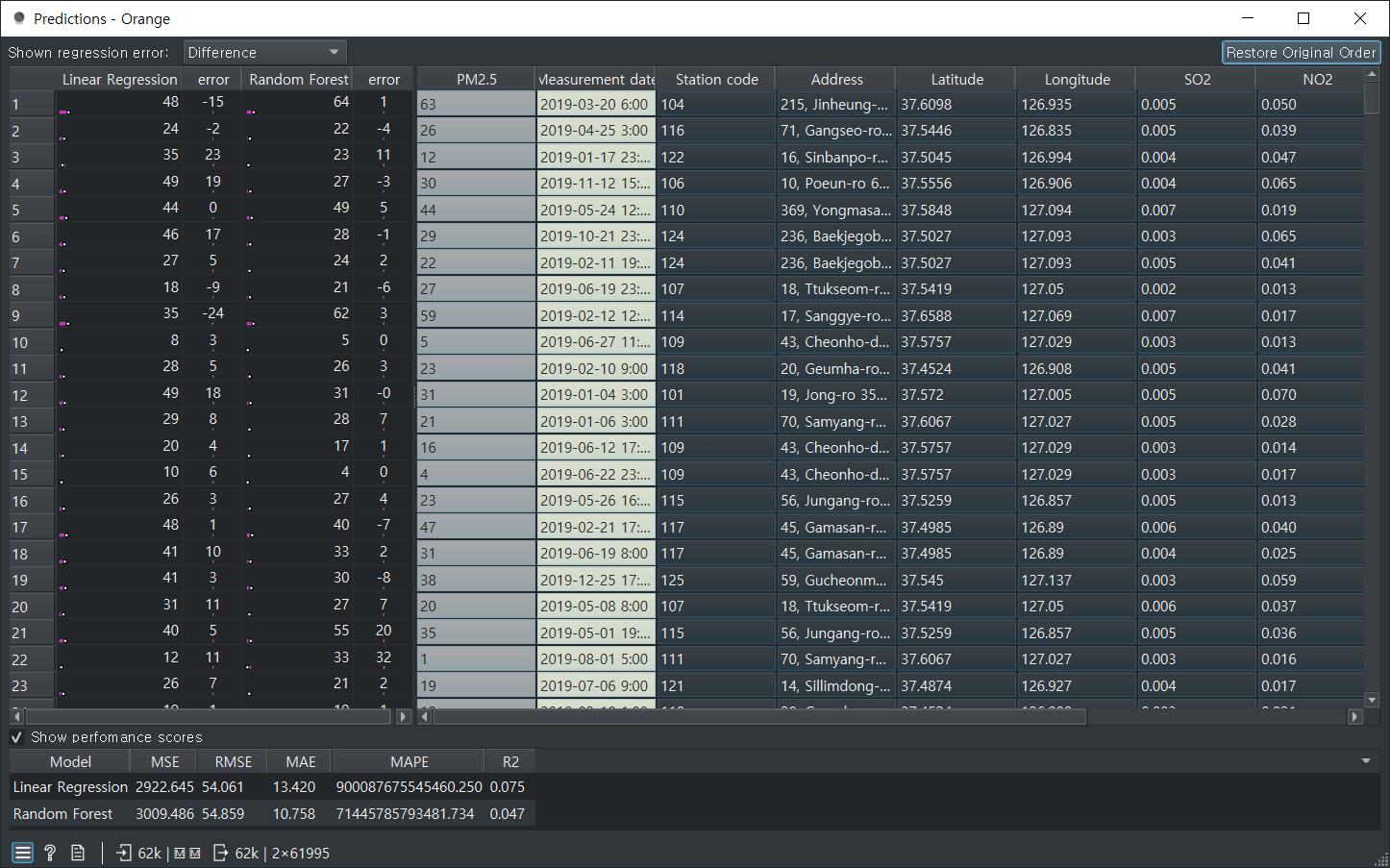
random forest가 낮은값으로 나온다.
할 때마다 결과값이 달리 나온다.
100번 정도 돌려서 화률이 높은것을 선택한다.
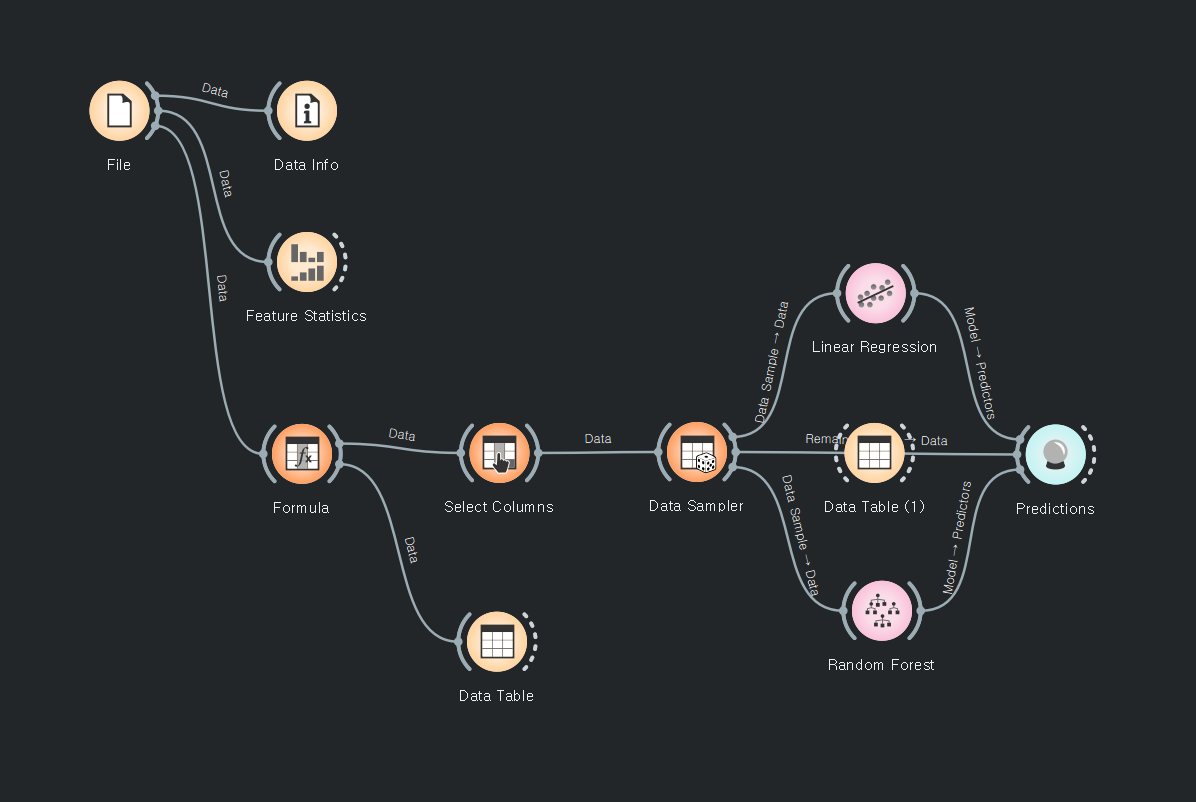
리니어는 선형이다 치수만 해석가능하다. 범주형은 불가능
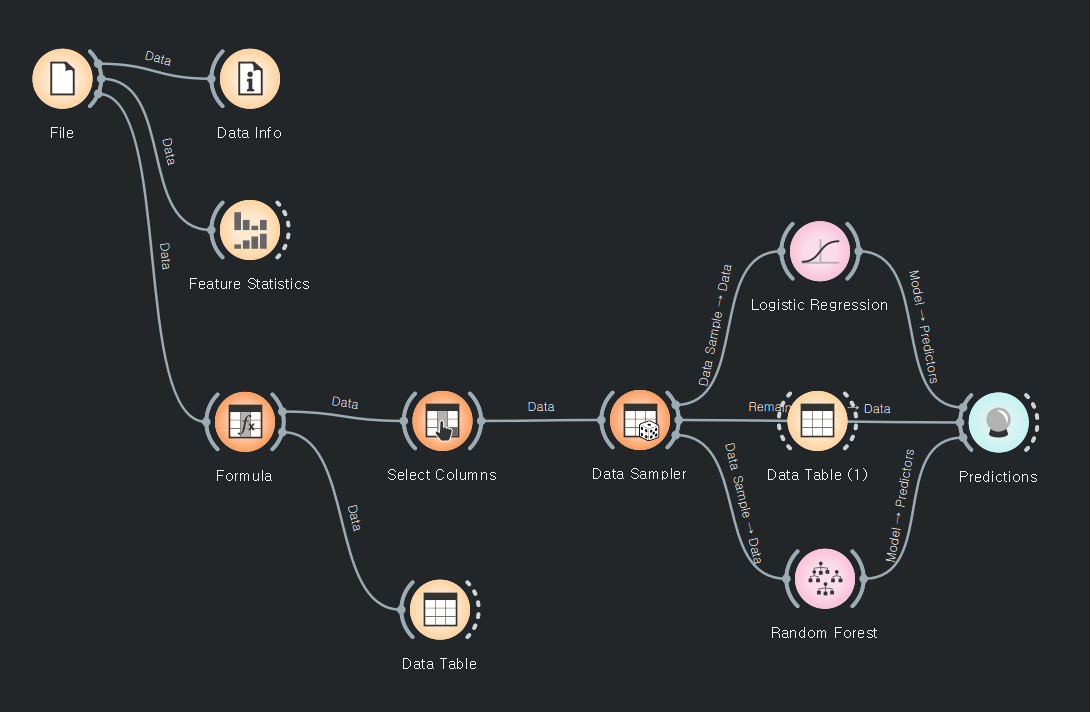
로지스틱 회귀로 변경됨.
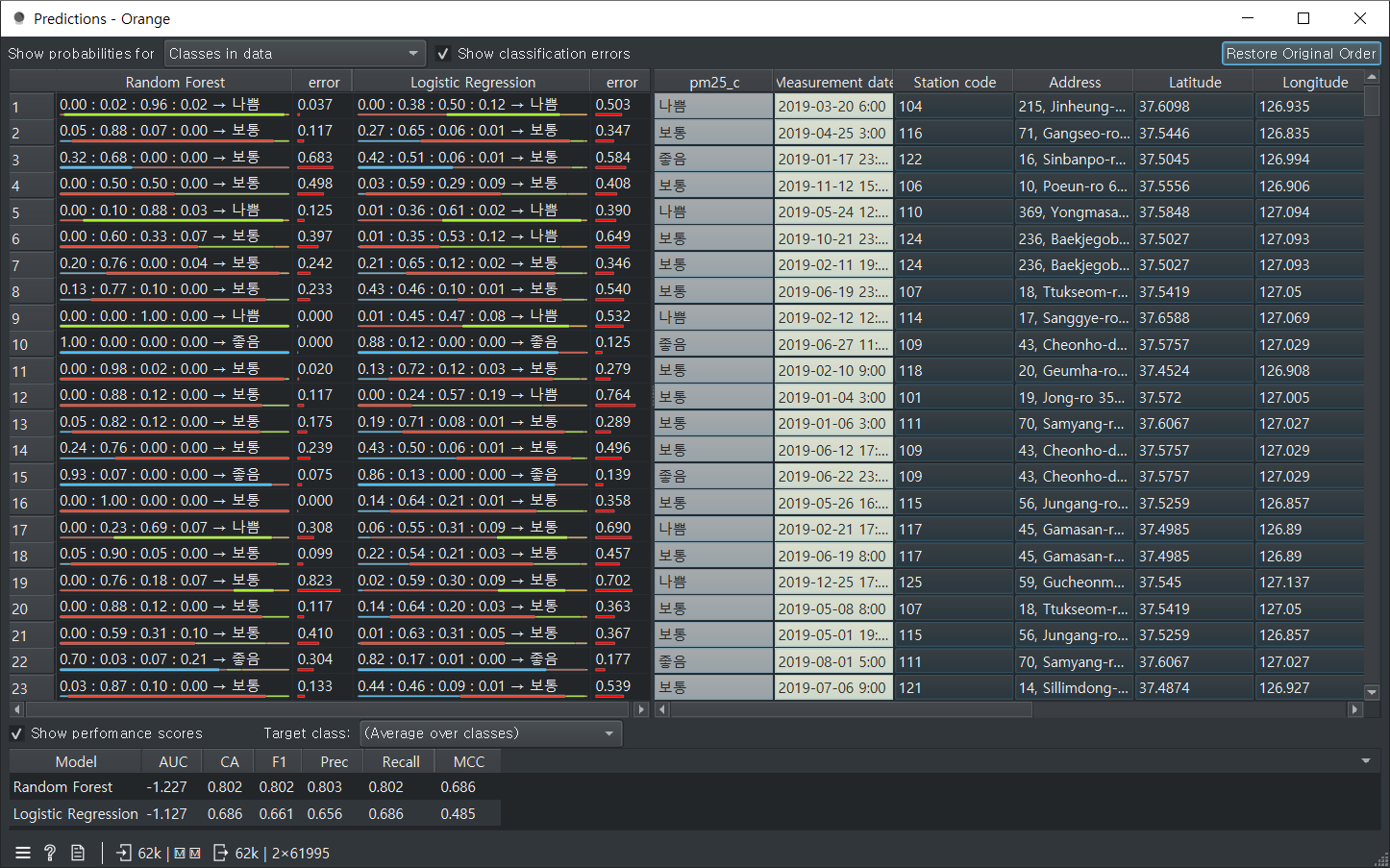
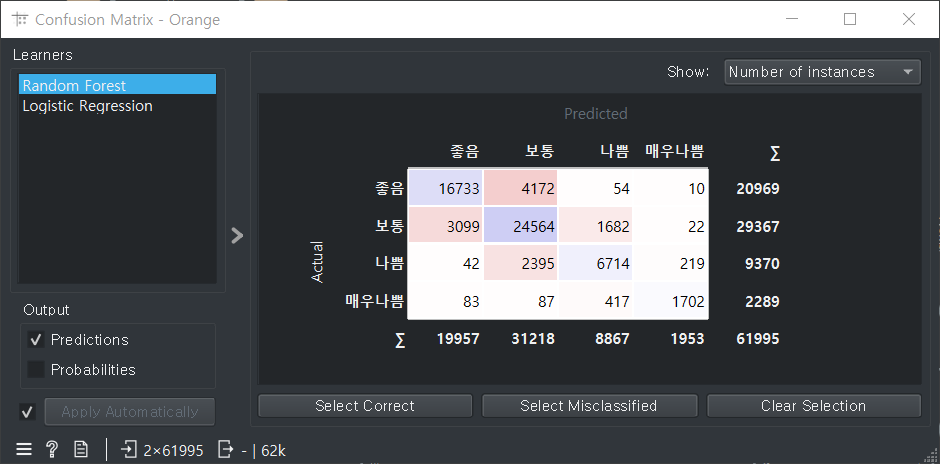
랜덤 포레스트 f1 0.802가 좋은 값이다.
시계열데이터의 대표 : 주가
미래를 예측할 때 주로 사용.
분산이 커지면 예측하기 어렵다.
주기, 계절, 분산 일정 => 제거하고 예측한다.
정상성이 있어야 예측이 가능하다.
주식
1) 가정
2) 분석, 검증
3) 가정=사실
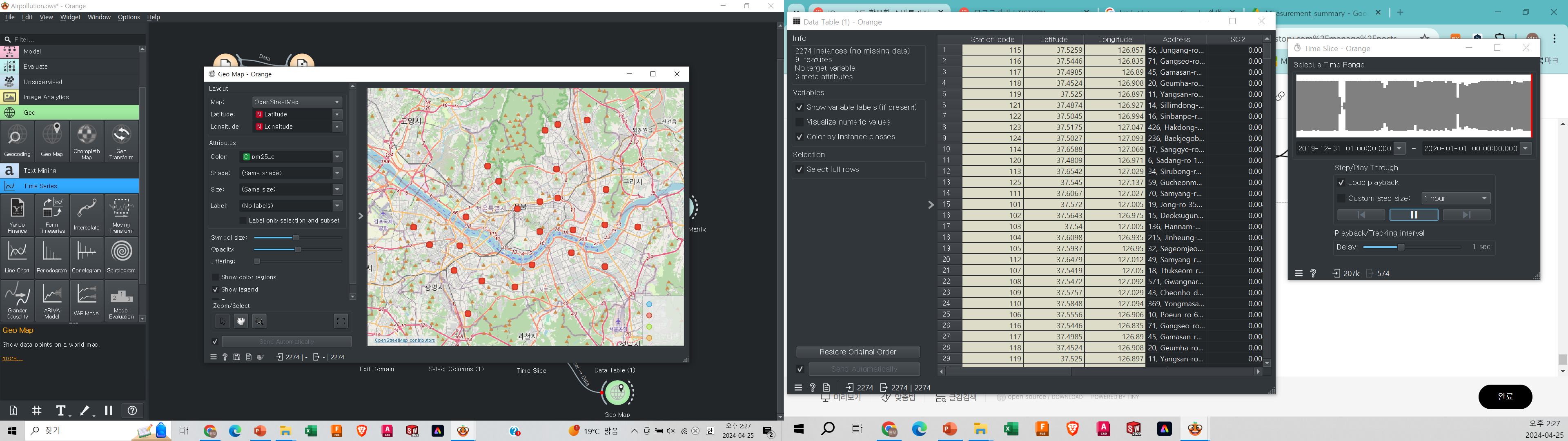
csv => ,또는 ; 로 열 분리를 한다.
txt => 탭 으로 열 분리를 한다.
csv를 오랜지에서 불러오는 순간, 관계는 끊어진다.
csv를 업데이트해봐야 오랜지에서는 업데이트가 안된다.
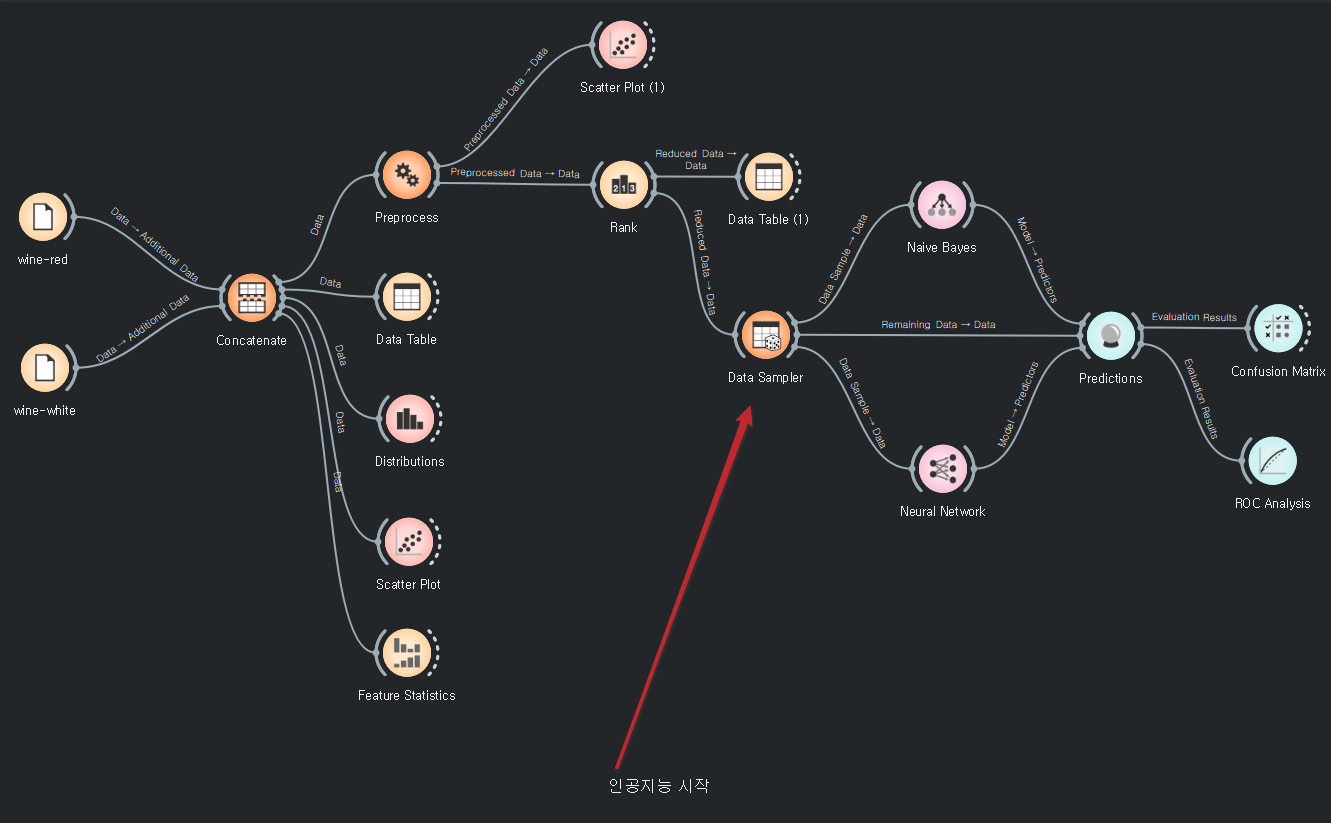
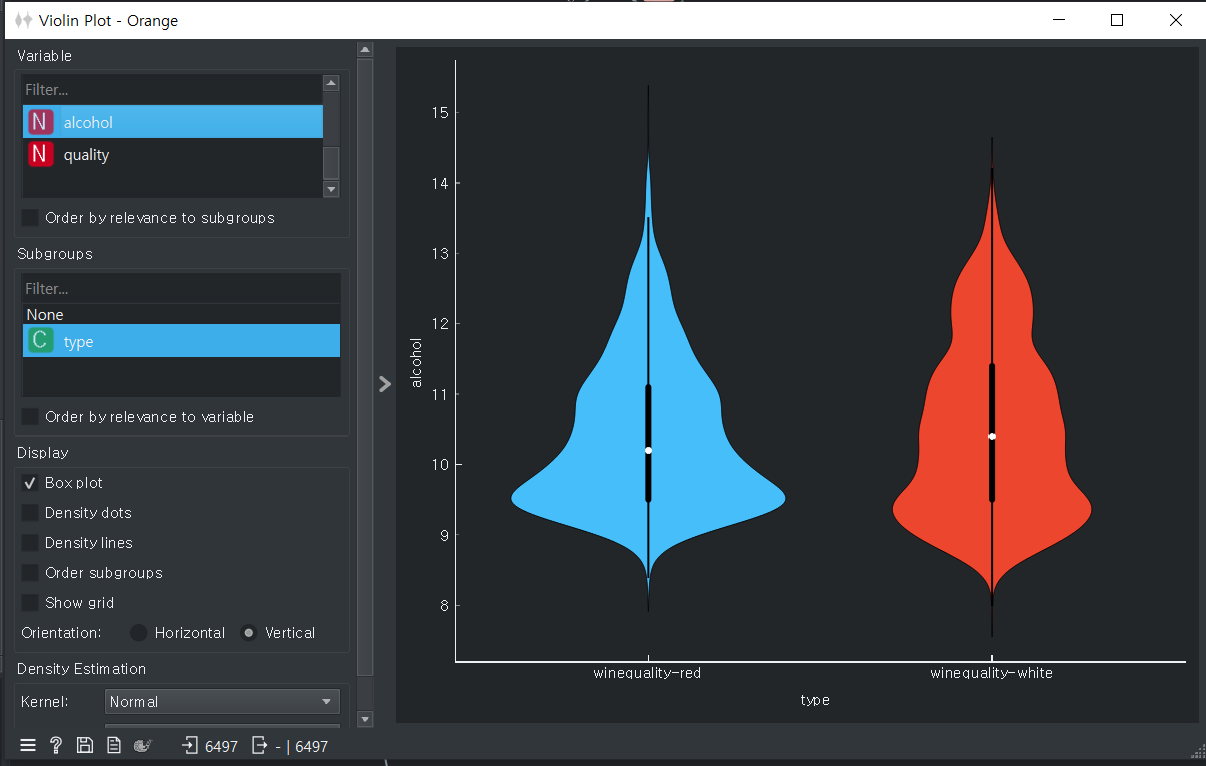
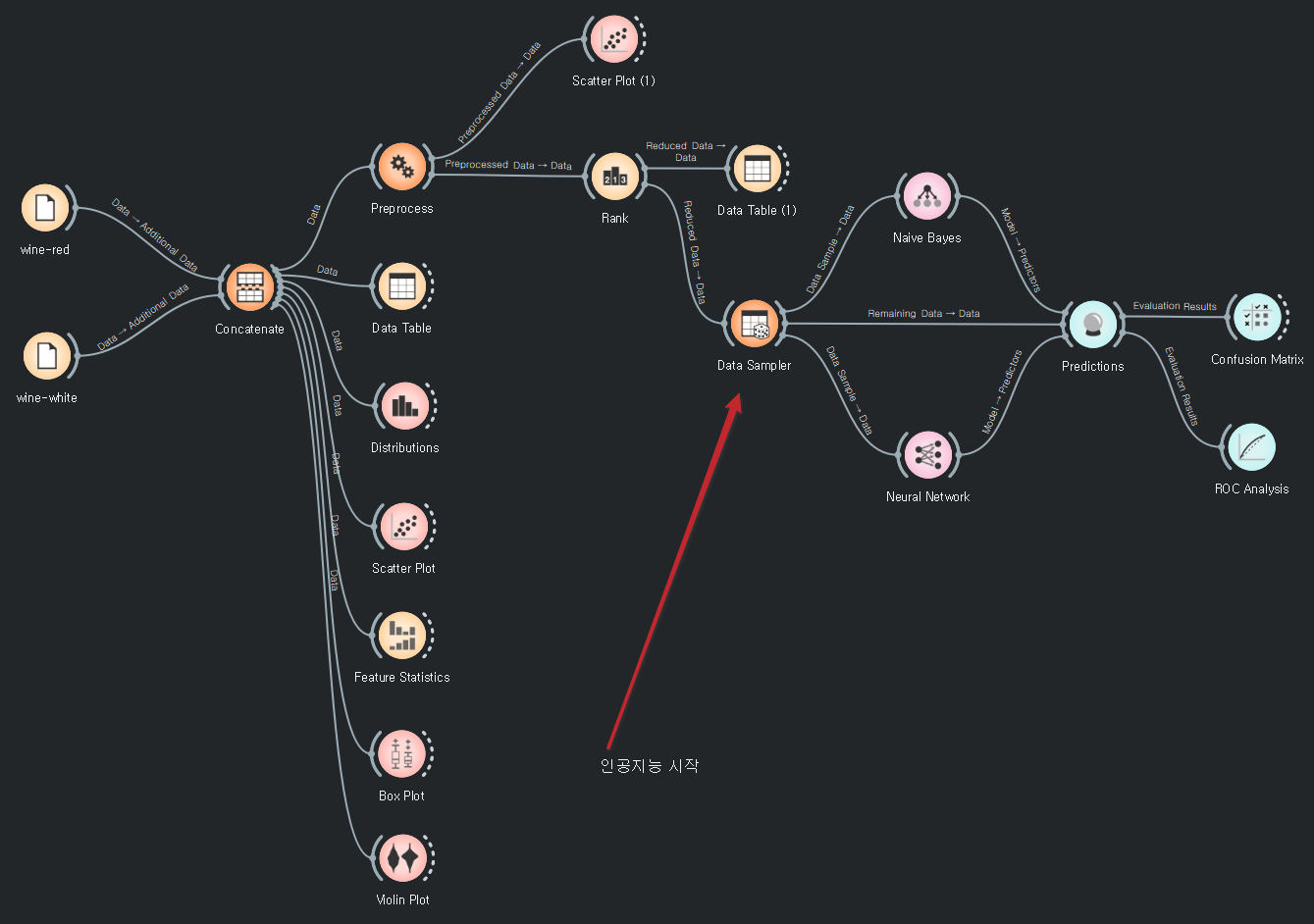
와인분류
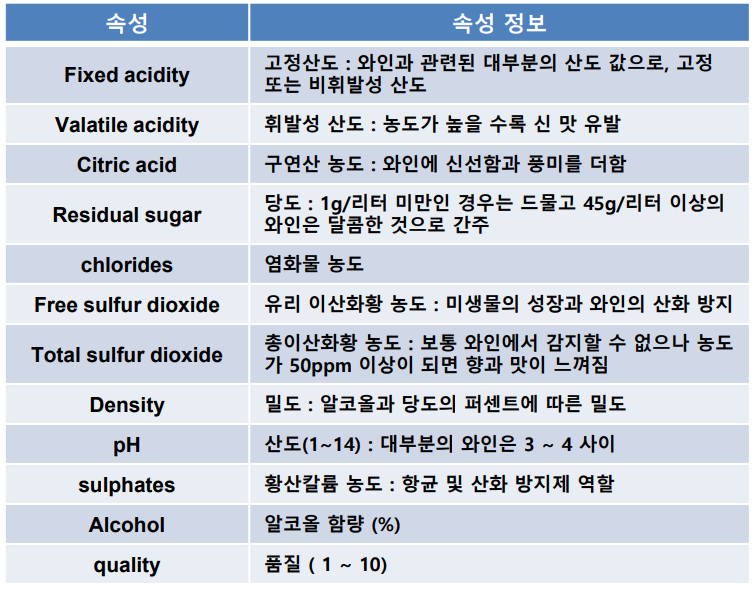
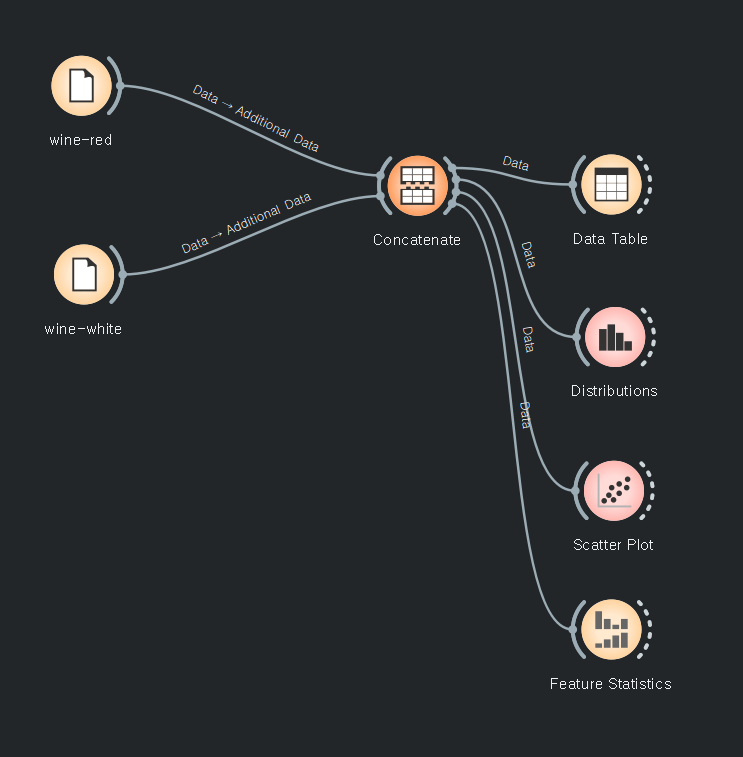
4가지를 기본으로 삼고 예측한다.
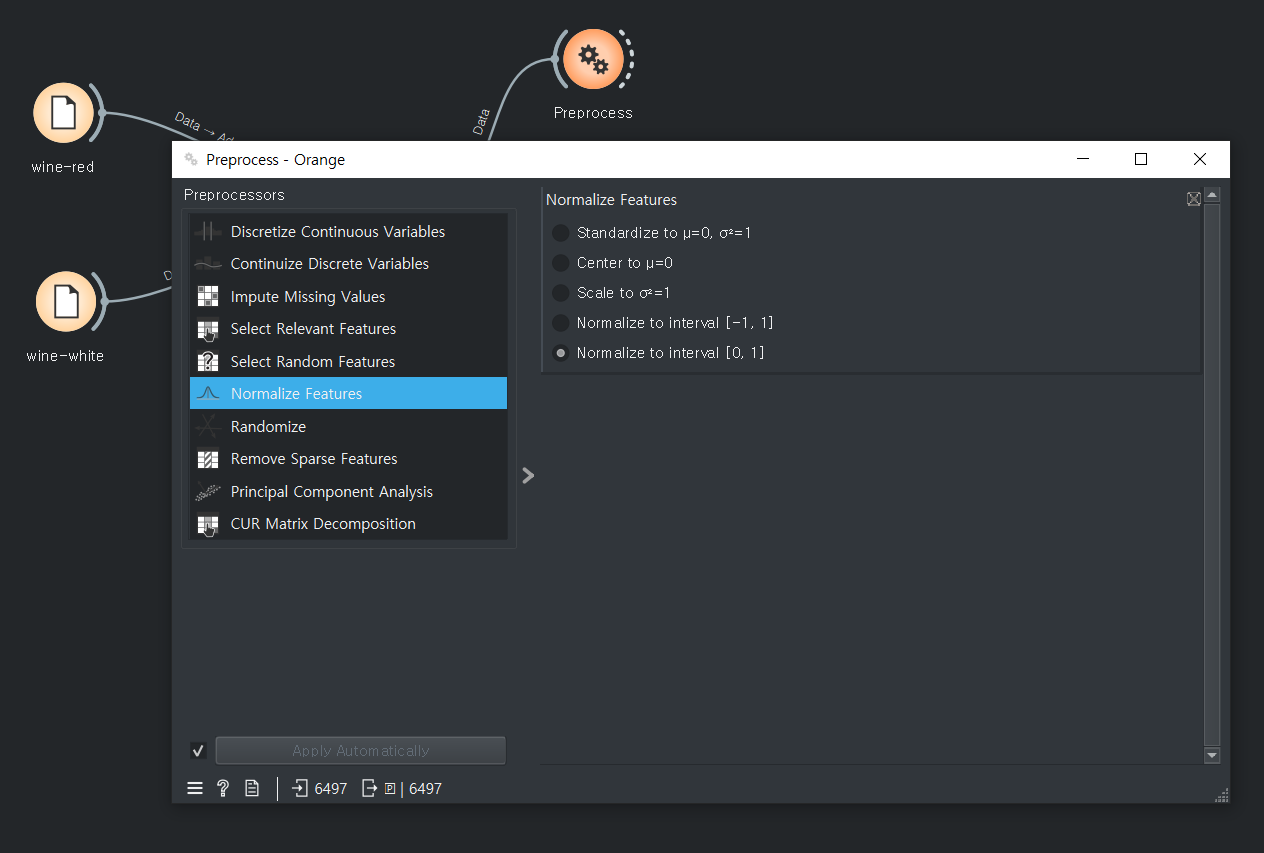
값을 0~1값으로 바꿔준다.
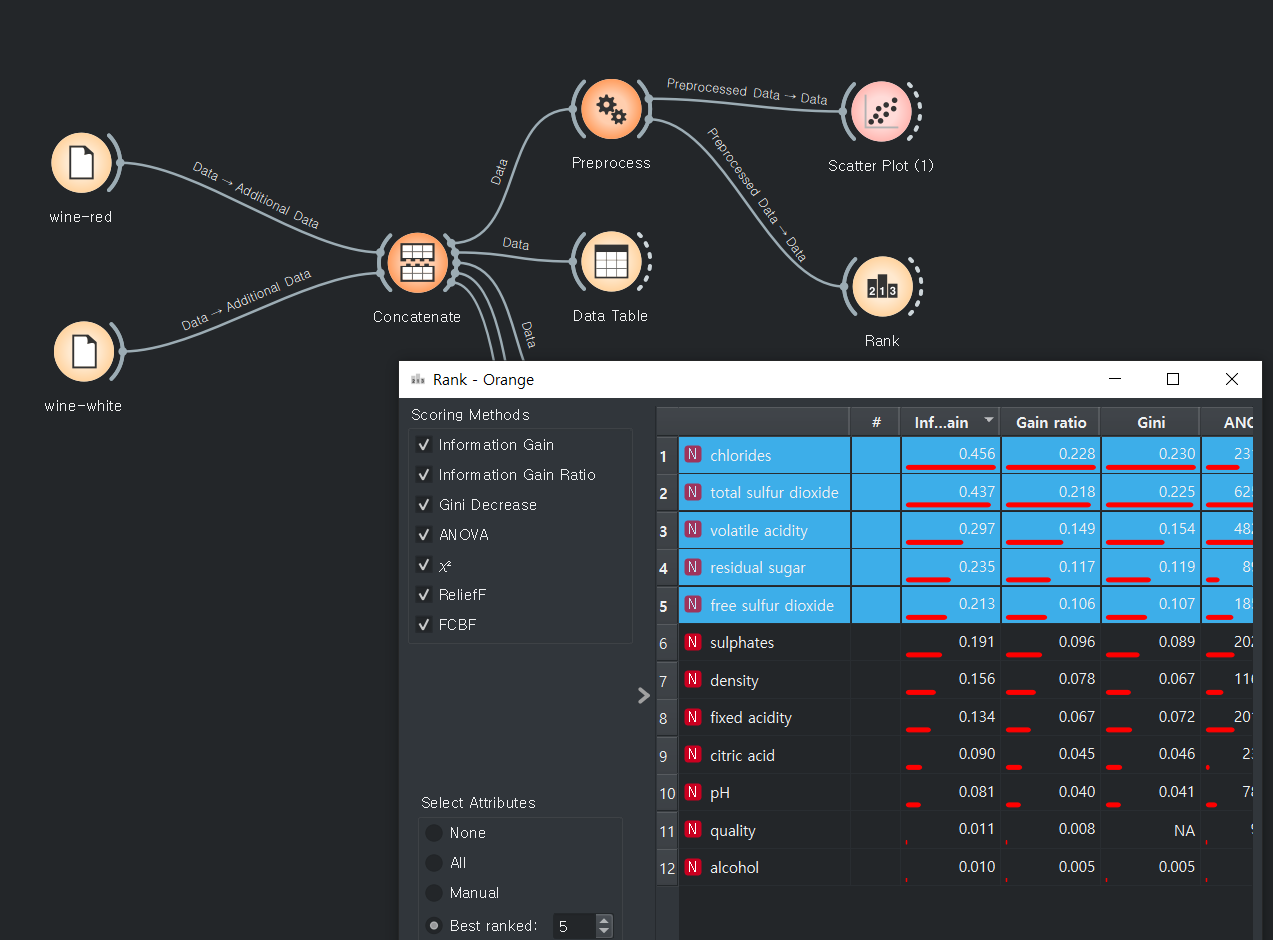
전처리 후에는 랭크를 알아서 어느정도 정리해준다.
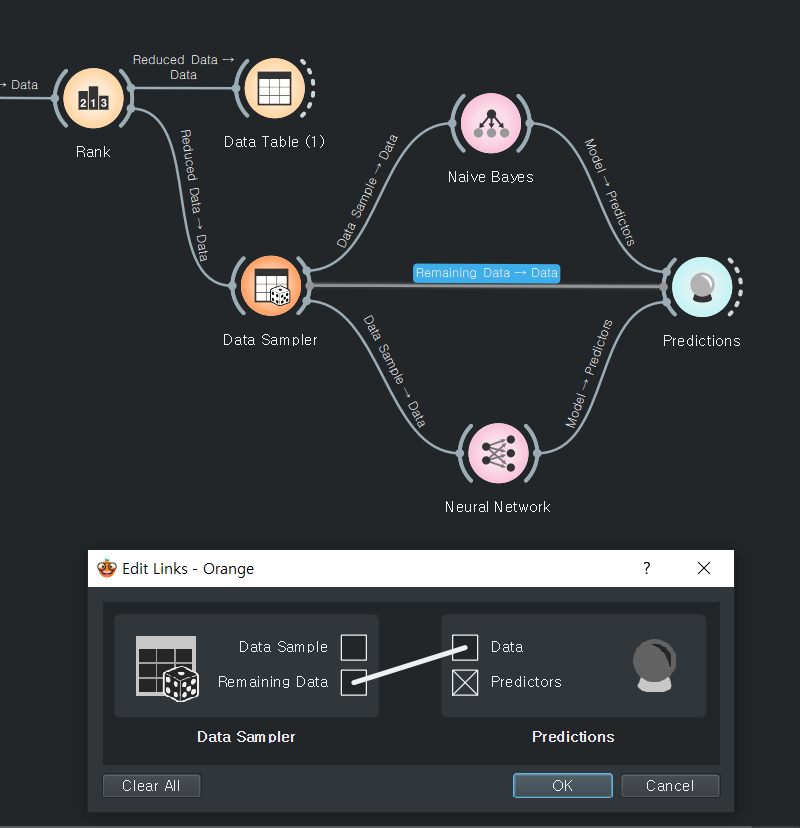
남아있는 데이터도 연결해준다.
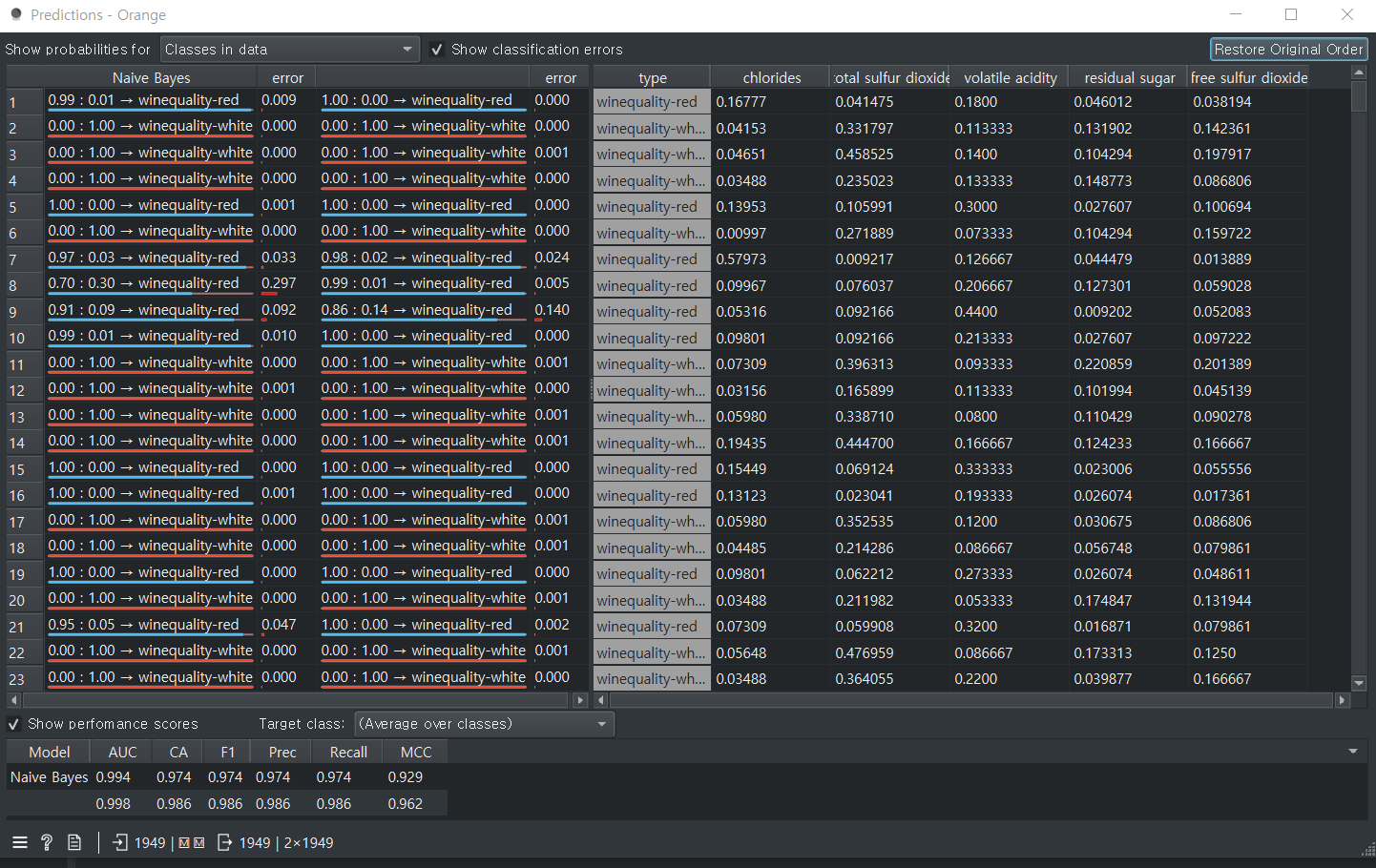
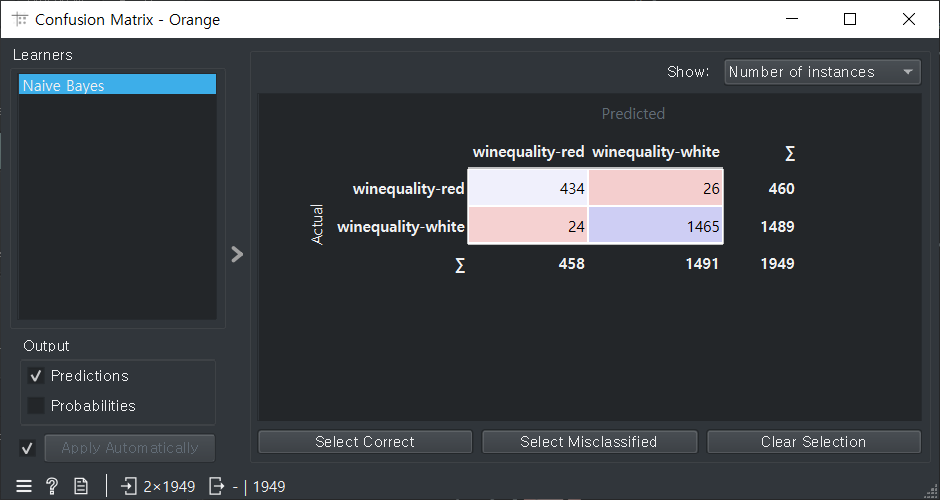
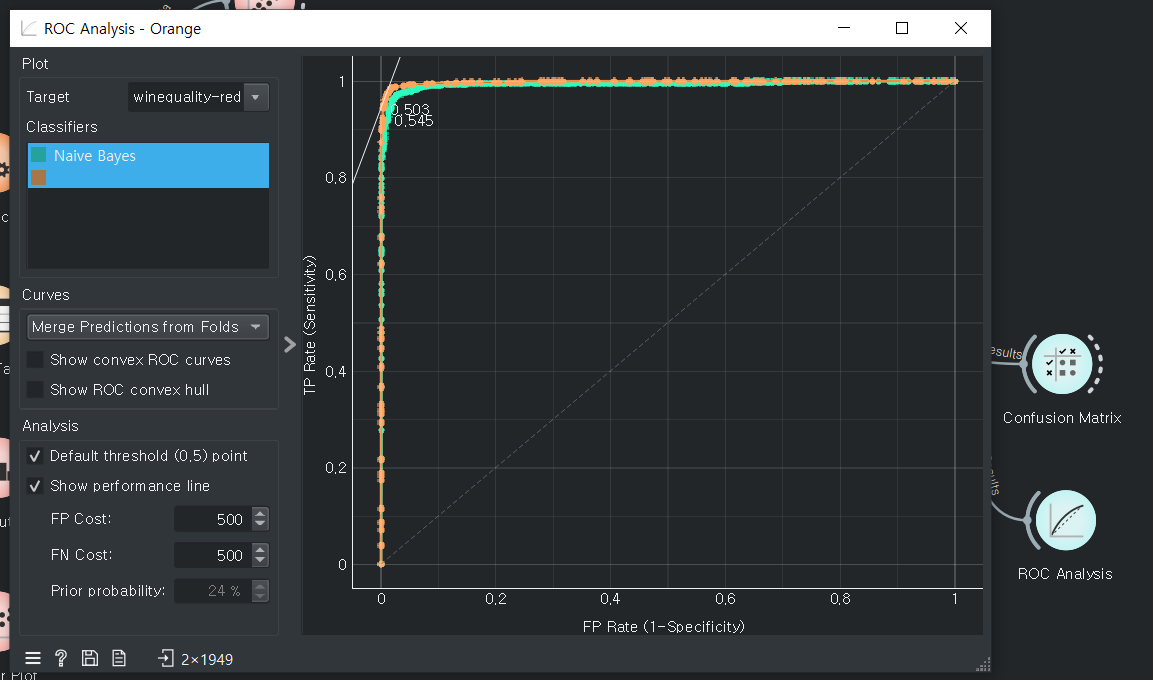
ROC Analysis
'KOSME 중소벤처기업' 카테고리의 다른 글
| ORANGE 3 YOUTUBE 친절한 AI (0) | 2024.04.23 |
|---|
