1. 데이터베이스의 구성요소에 대한 설명이다. 각각 무엇에 대한 설명인가?
가. 데이터를 설명해주는 데이터로 데어터의 특성, 구조, 정의 및 관ㄹ 정보를 설명하는 데이터
나. 데이터를 빠르고 쉽게 찾을 수 있게 해주는 자료구조
1) 가: 테이블, 나: 인덱스
2) 가 : 메타데이터, 나 : 인덱스
3) 가 : 메타데이터, 나 : 속성
4) 가 : 테이블 , 나 : 속성
| 구분 | 설명 |
| 메타데이터(Metadata) | - 데이터에 대한 데이터로 데이터의 특성, 구조, 정의 및 관리 정보를 설명하는 데이터 - 데이터의 구조와 의미를 이해하고 데이터를 관리, 검색 및 분석하는데 필수적 |
| 인덱스(Index) | - 데이터베이스에서 데이터 검색 및 조회의 성능을 향상시키기 위해 사용되는 자료구조 - 키는 검색을 빠르게 수행하기 위한 정렬 및 검색 구조를 제공함. |
| 테이블(Table) | - 표 형식의 행과 열로 구성된 데이터 |
| 속성(Attribute) | - 테이블에서 하나의 열(Column)에 해당하는 데이터 |
2. 다음 중 상용 DB가 아닌 것은 무엇인가?
1) DB2
2) Tableau
3) SQL Server
4) Oracle
- Tableau는 데이터 시각화 및 BI도구로, 데이터를시각적으로 탐색하고 이해하며 인사이트를 발견하는 데 사용되는 강력한 소프트웨어로 데이터 시각화, 대시보드 및 리포트 작성, 뎅터 연결 및 준비, 뎅터 분석, 대규모 데이터 집합 관리 등 다양한 데이터 관련 작업을 지원함.
상용 DB 종류
- Oracle Database
- Microsoft SQL Server
- IBM Db2
- SAP HANA
- PostgresSQL
- My SQL(무료/유료)
- Amazon RDS (Amazon Relational Database Service)
- Maria DB
- Teradata
- Sybase ASE(Adaptive Server Enterprise)
3. 데이터의 크기를 작은 것부터 큰 것 순서대로 올바르게 나열한 것은?
1) PB < EB < ZB < YB
2) PB < YB < EB < ZB
3) YB < ZB < EB < PB
4) PB < ZB < EB < YB
KB < MB < GB < TB < PB < EB < ZB < YB (Peta < Exa < Zetta < Yotta)
PB=10^15 < EB=10^18(백경) < ZB=10^21(십해) < YB=10^24
4. 데이터베이스의 특징에 대한 설명 중 옳지 않은 것은 무엇인가?
1) 통합된 데이터로 동일한 내용의 데이터가 중복되어 저장된다.
2) 저장된 데이터로 컴퓨터가 접근할 수 있는 저장매체에 저장된다.
3) 공용 데이터로 여러 사용자에게 서로 다른 목적으로 데이터가 공동 이용된다.
4) 변화되는 데이터로 항상 변화하면서도 항상 현재의 정확한 데이터를 유지해야 한다.
| 구분 | 특징 |
| 통합 데이터 | 데이터베이스에 같은 내용의 데이터가 중복되어 있지 않다는 것을 의미 |
| 저장 데이터 | 자기디스크나 자기테이프 등과 같이 컴퓨터가 접근 할 수 있는 저장매체에 저장되는 것을 의미 |
| 공용 데이터 | 여러 사용자에게 서로 다른 목적으로 데이터베이스의 데이터를 공동으로 이용되는 것을 의미 |
| 변화되는 데이터 | 새로운 데이터의 추가, 기존 데이터의 삭제, 갱신으로 항상 변화하면서도 항상 현재의 정확한 데이터를 유지해야 한다는 것을 의미 |
5. 빅데이터 활용을 위한 3요소에 대한 내용으로 틀린 것은?
1) 데이터 : 모든 것의 데이터화
2) 기술 : 진화하는 알고리즘, 인공지능
3) 인력 : 데이터 사이언티스트, 알로리즈미스트
4) 프로세스 : 이전과는 다른 데이터 관리를 위한 작업 절차
- 빅데이터 활용을 위한 3요소
| 데이터(자원) | 모든 것의 데이터화(Datafication) |
| 기술 | 진화하는 알고리즘, 인공지능 |
| 인력 | 데이터 사이언티스트, 알고리즈미스트 |
데이터 거버넌스(조직) 구성요소
| 원칙 | 데이터를 유지 관리하기 위한 지침과 가이드 및 보안, 품질 기준, 변경 관리 |
| 조직 | 데이터를 관리할 조직의 역할과 책임 및 데이터 관리자, 데이터 아키텍트 |
| 프로세스 | 데이터 관리를 위한 활동과 체계 및 작업 절차, 모니터링 활동 |
6. 빅데이터로 인한 본질적인 변화로 옳지 않은 것은?
가. 이미 가치가 있을 것으로 정해진 특정한 정보만 모아서 처리하던 것에서 가능한 많은 데이터를 모으고 다양한 방식으로 조합해 숨은 정보를 찾아낸다.
나. 일부 데이터의 샘플링을 통한 표본조사를 수행하는 환경으로 변화되었다.
다. 질보다 양의 관점을 갖는다.
라. 인과관계에 의한 미래 예측이 데이터 기반의 상관관계, 분석을 점점 더 압도하는 추세이다.
1) 가, 나
2) 나, 라
3) 가, 다
4) 다, 라
빅데이터의 본질적 변화사전처리 -> 사후처리표본조사 -> 전수조사질(Quality) -> 양(Quantity)인과관계 -> 상관관계
7. 빅데이터의 위기요인이 아닌 것은?
1) 익명화
2) 사생활 침해
3) 데이터 오용
4) 책임원칙의 훼손
2) 사생활 침해 -> 동의제를 책임제로 전환
3) 데이터 오용 -> 데이터 알고리즘에 대한 접근권 허용 및 객관적 인증방안을 도입 필요성 제기
4) 책임원칙의 훼손 -> 기존의 책임원칙을 강화
8. 데이터 사이언티스트가 자져야 할 역량 중 종류가 다른 하나는?
1) 다분야간 협력
2) 통찰력있는 분석
3) 설득력있는 전달
4) 빅데이터에 대한 이론적 지식
데이터 사이언티스트의 역량
| 하드 스킬 | Machine Learning, Modeling, Data Technical Skill |
| 소프트 스킬 | 통찰력있는 분석, 설득력있는 전달, 다분야간 협력 |
9. 기업이 외부 공급업체 또는 제휴업체와 통합된 정보시스템으로 연계하여 시간과 비용을 최적화 시키기 위한 솔루션은 무엇은가?
SCM (Supply Chain Management)
10. 데이터, 정보, 지식을 통해 최종적으로 지혜를 얻어내는 과정을 계층구조로 설명하는 것은 무엇인가?
DIKW
| Data(데이터) | 타 데이터와의 상관관계가 없는 가공하기 전의 순수한 수치나 기초 |
| Information(정보) | 데이터의 가공 및 상관/연관 관계 속에서 의미가 도출된 것. |
| Knowledge(지식) | 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물 |
| Wisdom(지혜) | 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 아이디어 |
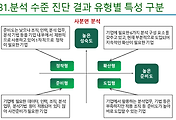
11. 데이터 분석 수준 진단 결과에서 분석 준비도와 분석 성숙도 둘 다 낮은 경우에 해당하는 것은?
1) 정착형
2) 확산형
3) 준비형
4) 도입형
| 준비형 (준비도 낮음, 성숙도 낮음) |
기업에 필요한 데이터, 인력, 조직, 분석업무 등이 적용되어 있지 않아 사전준비가 필요한 기업 |
| 도입형 (준비도 높음, 성숙도 낮음) |
기업에서 활용하는 분석업무, 기법 등은 부족하지만, 적용 조직 등 준비도가 높아 바로 도입 가능한 기업 |
| 정착형 (준비도 낮음, 성숙도 높음) |
준비도는 낮으나 기업 내부에서 제한적으로 사용하고 있어, 1차적으로 정착이 필요한 기업 |
| 확산형 (준비도 높음, 성속도 높음) |
기업에 필요한 6가지 분석 구성요소를 갖추고 있고, 부분적으로도 도입되어 지속적 확산이 필요한 기업 |

12. 비즈니스 모델 캔버스를 활용한 과제 발굴의 영역으로 틀린 것은?
1) 혁신
2) 업무
3) 고객
4) 제품
비즈니스 모델 캔버스 5가지 영역 : 업무, 제품, 고객, 지원 인프라, 규제와 감사
13. 분석과제의 우선순위 선정 관련 설명 중 틀린 것은?
1) 우선순위를 시급성에 둔다면 3-4-2 순서로 진행한다.
2) 우순순위를 난이도에 둔다면 3-1-2 순서로 진행한다.
3) 시급성과 난이도 둘 다 높은 것이 우선순위가 가장 높다.
4) 시급성의 판단기준은 전략적 중요도가 핵심이다.
하단의 1,2,3,4 분면, 난이도, 시급성 방향을 암기할 것. 우선순위가 아닌것 한가지는 제외된다.

14. 분석 성숙도 관련 내용으로 옳지 않은 것은?
1) 유사 업종, 경쟁업체와의 비교분석을 포함한다.
2) 성숙도 수준에 따라 도입, 활용, 확산, 최적화 단계로 구분해 살펴 볼 수 있다.
3) 시스템 개발 업무능력과 조직의 성숙도 파악을 위해 CMMI 모델을 활용하여 분석 성숙도를 평가한다.
4) 데이터 분석 수준 진단은 분석 준비도와 분석 성숙도를 함께 평가함으로써 수행될 수 있다.
- 분석 성숙도 수준 진단은 주로 기업 내부의 데이터 분석 능력과 프로세스에 대한 평가를 다룬다.
- 시스템 개발 업무능력과 조직의 성숙도 파악을 위해 CMMI 모델을 활용하여 분석 성숙도를 평가한다.
- 비즈니스 부문, 조직/역량 부문, IT부문을 대상으로 성숙도 수준에 따라 도입, 활용, 확산, 최적화 단계로 구분해 살펴 볼 수 있다.
- 데이터 분석 수준 진단은 분석 준비도와 분석 성숙도를 함께 평가함으로써 수행될 수 있다.

15. 분석 마스터플랜 수립 시 적용/방식의 고려요소가 아닌 것은?
1) 업무 내재화 적용 수준
2) 분석 데이터 적용 수준
3) 기술 적용 수준
4) 실행 용이성
우순순위 고려요소 : 전략적 중요도, ROI(투자자본 수익률), 실행용이성
적용 범위/방식 고려요소 : 업무 내재화 적용수준, 분석 데이터 적용 수준, 기술 적용 수준
16. 데이터 분석을 위한 분석 업무 조직 구조에 대한 설명으로 옳지 않은 것은?
1) 집중형 조직 구조는 일부 협업 부서와 분석 업무가 중복 또는 이원화될 가능성이 있다.
2) 기능 중심 조직 구조는 전사적 관점에서 핵심 분석이 어렵다.
3) 분산 조직 구조는 분석 결과 실무 적용에 대한 대응이 느리다.
4) 분석 조직의 인력들이 협업부서에 배치되어 업무를 수행하는 것은 분산 조직 구조이다.
분산 조직 구조
- 분석 조직의 인력들이 협업부서에 배치되어 업무를 수행
- 전사 차원에서 분석 과제의 우선순의를 선정해 수행, 분석 결과를 신속하게 실무 적용 가능
- 부서 분석 업무와 역할 분담을 명확해야한다.
17. 분석 활용 시나리오에 대한 설명으로 틀린 것은?
1) 데이터 확보가 가장 중요하다.
2) 데이터 분석을 특정 목적에 맞게 활용하는 방법 또는 계획을 의미한다.
3) 분석 목표와 분석 방법을 설명하고 예상 결과를 제시하는 문서이다.
4) 프로젝트 진행 중에도 변경될 수 있다.
분석 활용 시나리오
- 분석 활용 시나리오에서 가장 중요한 것은 데이터 확보보다 목표와 목적이다.
- 목표와 목적을 명확하게 이해하고 정의하는 것은 분석 프로젝트의 핵심 요소 중 하나이다.
- 목표와 목적을 정의하지 않으면 데이터확보, 분석, 결과에 대한 계획을 수립하기 어려울 수 있다.
- 데이터는 목표를 달성하고 목적을 실현하기 휘한 도구로 사용된다.

18. 분석 기획 시 고려해야 할 것으로 적적하지 않은 것은?
1) 데이더 확보가 될 수 있는지, 데이터 유형에 대한 분석이 필요하다.
2) 비용보다 분석력에 최우선 해야 한다.
3) 기존에 잘 구현되어 활용되고 있는 유사 시나리오 및 솔루션을 최대한 활용한다.
4) 장애요소에 대한 사전 계획 수립이 고려되어야 한다.
분석기획 시 고려사항
- 가용한 데이터 : 데이터의 유형분석이 선행적으로 이루어져야 한다.
- 적절한 유즈케이스 탐색 : 유사분석 시나리오 솔루션이 있다면 이것을 최대한 활용한다.
- 장애요소들에 대한 사전 계획 수립 필요
* 일반적으로 비용과 분석력은 상호 보완적인 요소로 고려되며, 적절한 균형을 유지해야 한다.
19. 아래 설명의 답을 작성하시오.
< 데이터 분석 준비도 프레임워크에서 운영시스템 통합, EAI, ETL 등 데이터 유통체계, 분석 전용 서버 및 스토리지, 빅데이터 분석 환경, 비주얼 분석 환경 등과 관련된 항목은 무엇인가? >
분석인프라
20. 아래 설명을 읽고 빈칸 ( )을 작성하시오.
< 기존의 논리적인 단계별 접근법에 기반한 문제해결 방식은 최근 복잡하고 다양한 환경에서 발생하는 문제에 적합하지 않을 수 있다. 이를 해결하기 위해 ( )접근법을 통해 전통적인 분석적 사고를 극복하려고 한다.
이 접근법은 상향식 방식의 발산단계와 도출된 옵션을 분석하고 겁증하는 하향식 접근 방식의 수렴단계를 반복하여 과제를 발굴한다.
디자인사고
21. 수면유도제 데이터를 통한 t-test 결과이다. 결과해석이 적절하지 않은 것은?
> t.test(extra~group, data=sleep, var.equal=TRUE)
Two Sample t-test
data: extra by group
t = -1.8608, df = 18, p-value = 0.07919
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.363874 0.203874
sample estimates:
mean in group 1 mean in group 2
0.75 2.33
1) 수면유도제 2가 수면유도제 1보다 효과적이다.
2) 유의수준 0.05이하에서 두 집단의 평균이 동일하다는 귀무가설을 채택할 수 있다.
3) 두 개의 표본집단이 크기가 클 경우(N>30) 잡단이 정규성 검정없이 이 표본 t검정을 사용할 수 있다.
4) 독립표본 t검정 분석 전에 등분산 검정을 실시한다.
두 집단 평균이 동일하다라는 귀무가설을 채택할 수 있으므로, 수면유도제2가 더 효과적이라 할 수 없다.
22. 분류모형 평가에 사용되는 도구가 아닌 것은?
1) ROC그래프
2) 덴드로그램
3) 향상도곡선
4) 이익도표
- 회귀모형 평가도구 : MAE, MAPE, MSE, RMSE, MLSE, RMSLE, 결정계수 등
- 분류모형 평가도구 : 오분류표(혼동행렬), ROC 그래프, 향상도 곡선, 이익도표, Kappa 등
- 군집모형 평가도구 : 실루엣 계수(Silhouette Coefficient), Dunn Index 등
- 덴드로그램(Dendrogram) : 클리스터링의 결과를 시각화하기 위한 대표적인 그래프입니다. 대표적으로 계측적 군집분석(Hierachical Clustering) 방식에 대해 시각화하는 그래프로 많이 활용되고 있습니다. 즉, 가까운 두 점 혹은 점과 그룹을 묶어나가면서 그룹을 이루어나가는 과정을 시각화한 그래프입니다.

23. 증거가 확실할 때 가설검정으로 증명하고자 하는 것은?
1) 귀무가설
2) 영가설
3) 대립가설
4) 기각가설
-귀무가설 : 가설검정의 대상이 되는 가설, 연구자가 부정하고자 하는 가설, 알고 있는 것과 같음. 변화, 영향력, 연관성, 효과없음에 대한 가설
- 대립가설 : 연구자가 연구를 통해 입증/증명되기를 기대하는 예상이나 주장, 귀무가설이 기각되면 채택되는 가설
24. 성격이 다른 한가지는 무엇인가?
1) K-means
2) Single Linkage Method
3) DBSCAN
4) 주성분 분석
군집분석
- 계층적 군집분석 : 최소연결법, 최장연결법, 중심연결법, 평균연결법, 와드연결법
- 비계층적 군집 분석 : K-means, DBSCAN
- 비지도 신경망 : SOM
- 차원축소 : 주성분 분석, 다차원 척도법, 요인 분석 등이 있다.
25. 스피어만 상관계수 관련 설명으로 틀린 것은?
1) 스피어만 상관계수는 비선형적인 관계를 나타낼 수 없다.
2) 대상자료는 서열척도를 사용한다.
3) 원시 데이터가 아니라 각 변수에 대해 순위는 매긴 값을 기반으로 한다.
4) 연속형 외에 이산형 데이터도 사용 가능하다.
스피어만 상관계수
- 대상자료는 서열척도 사용, 두변수 간의 비선형적인 관계를 나타낼 수 있다.
- 연속형 외에 이산형도 가능하다.
- 스피어만 상관 계수는 원시 데이터가 아니라 각 변수에 대해 순위를 매긴 값을 기반으로 한다.
26. 비지도 신경망으로 고차원의 데이터를 이해가 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화하는 알고리즘을 무엇이라고 하는가?
1) SOM
2) DBSCAN
3) PCA
4) EM-알고리즘
SOM은 Self-Organizing Map의 약자이며, 데이터를 비지도학습으로 분류하는 데 사용되는 인공신경망 알고리즘입니다. SOM은 데이터의 특징을 보존하면서 저차원의 격자 형태의 맵에 투영하는 기술입니다. 이를 통해 데이터의 패턴이나 군집을 시각화하거나 차원 축소에 사용될 수 있습니다.
DBSCAN은 Density-Based Spatial Clustering of Applications with Noise의 약자로, 밀도 기반의 클러스터링 알고리즘입니다. DBSCAN은 주어진 데이터의 밀도를 기반으로 군집을 형성하며, 주변의 밀도가 높은 지역을 클러스터로 간주하고, 밀도가 낮은 지역을 경계로 나눕니다. 이 알고리즘은 잡음이 적고 밀도가 다양한 데이터에 효과적입니다.
PCA는 Principal Component Analysis의 약자로, 주성분 분석이라고도 합니다. PCA는 다차원 데이터를 저차원으로 차원 축소하는 기법 중 하나입니다. 이는 데이터의 분산을 최대한 보존하면서 주요한 특성을 추출하여 새로운 축으로 변환하는 방법입니다. PCA는 데이터의 차원을 줄이는 것뿐만 아니라, 데이터 시각화나 노이즈 제거에도 사용될 수 있습니다.
EM-알고리즘은 기대값 최대화(Expectation Maximization) 알고리즘의 줄임말입니다. 이 알고리즘은 데이터 분석과 머신 러닝에서 사용되며, 특히 관측되지 않은 미지의 변수가 있는 상황에서 파라미터 추정에 유용합니다. EM 알고리즘은 두 단계로 구성되어 있습니다:
Expectation 단계: 먼저, 파라미터의 초기 추정치를 설정합니다. 그런 다음, 주어진 데이터와 현재 추정치를 사용하여, 각 데이터 포인트가 어떤 잠재적인 클래스에 속할 가능성이 있는지 확률을 추정합니다.
Maximization 단계: 이후, 각 데이터 포인트가 속할 가능성이 있는 클래스에 대한 예상치를 사용하여, 파라미터를 다시 추정합니다. 이 단계에서는 최대 우도(Maximum Likelihood)나 최대 사후 확률(Maximum A Posteriori)을 최적화하여 파라미터를 업데이트합니다.
이러한 단계를 번갈아 가며 반복하면, EM 알고리즘은 파라미터를 점진적으로 개선하여 최적의 값을 찾습니다. 이 알고리즘은 클러스터링, 혼합 모델, 잠재 변수 모델 등 다양한 분야에서 사용됩니다.
27. 아래의 설명에 대항하는것을 고르시오.
< 공분산형렬 또는 상관계수 행렬을 사용해 모든 변수들을 가장 잘 설명하는 변수를 찾는 방법으로,
상관관계가 있는 변수들을 선형 결합에 의해 상관관계가 없는 새로운 변수를 만들고,
분산을 극대화하는 변수로 축약하는 방법으로 새로운 변수들은 변수들의 선형결합으로 이루어져 있다. >
1) 요인 분석
2) 회귀 분석
3) 주성분 분석
4) 다차원 분석
주성분분석(PCA, Principal Component Analisis)
- 공분산행렬 또는 상관계수 행렬을 사용해 모든 변수들을 가장 잘 설명하는 주성분을 찾는 방법
- 상관관계가 있는 변수들을 선형 결합에 의해 상관관계가 없는 새로운 변수(주성분)를 만들고 분산을 극대화하는 변수는 축약한다.
- 주성분은 변수들의 선형결핍으로 이루어져 있다.
- 독립변수들과 주성분과의 거리인 '정보손실량'을 최소화하거나 분산을 최대화한다.
요인분석(Factor Analysis):
요인분석은 다변량 통계 기법 중 하나로, 변수들 간의 상호 관계를 파악하여 관련성 있는 변수들의 패턴을 식별하는 데 사용됩니다. 이를 통해 변수들 간의 상관관계를 요인(잠재변수)으로 축약하고, 데이터의 차원을 줄이는 데 도움이 됩니다.
요인분석은 주로 데이터 간의 복잡한 패턴이나 구조를 이해하고 설명하는 데 활용됩니다. 예를 들어, 마케팅 연구에서 제품에 대한 소비자의 선호도를 분석하거나, 심리학 연구에서 특정 행동이나 성격 특성을 이해하는 데 사용될 수 있습니다.
회귀분석(Regression Analysis):
회귀분석은 종속 변수와 한 개 이상의 독립 변수 간의 관계를 분석하는 통계 기법입니다. 종속 변수의 값을 예측하기 위해 독립 변수들의 영향력을 조사하고 모델링하는 데 사용됩니다.
회귀분석은 예측 모델을 구축하거나 변수 간의 인과 관계를 이해하는 데 유용합니다. 경제학에서는 주가나 소비량 등을 예측하는 데 사용되며, 공학 분야에서는 제품의 성능을 예측하거나 설계 변수들 간의 관계를 분석하는 데 활용될 수 있습니다.
주성분분석(Principal Component Analysis):
주성분분석은 다변량 데이터에서 변수들 간의 상관 관계를 고려하여 변수들을 새로운 직교 좌표축으로 변환하는 기법입니다. 이를 통해 데이터의 차원을 줄이고, 변수들 간의 패턴을 파악할 수 있습니다.
주성분분석은 데이터의 차원 축소와 잠재된 구조를 발견하는 데 주로 사용됩니다. 예를 들어, 고차원의 이미지 데이터를 주성분분석을 통해 저차원의 특성으로 축소하여 처리하거나, 다변량 실험 결과를 분석하여 의미 있는 변수들을 도출하는 데 활용될 수 있습니다.
다차원분석(Multidimensional Analysis):
다차원분석은 다차원 데이터의 구조를 이해하고 시각화하기 위한 분석 기법을 의미합니다. 주로 데이터를 공간상에 표현하여 변수들 간의 관계나 패턴을 시각적으로 파악하는 데 사용됩니다.
다차원분석은 데이터 시각화나 군집화 등 다양한 분석 목적으로 활용됩니다. 예를 들어, 다차원 척도법(MDS)을 사용하여 비슷한 특성을 가진 데이터들을 군집화하거나, 고차원의 데이터를 저차원으로 시각화하여 패턴을 파악하는 데 활용될 수 있습니다.
28. 확률 및 확률분포에 관한 설명으로 틀린 것은?
1) (사건 A가 일어나는 경우의 수) / (일어날 수 있는 모든 경우의 수)를 P(A)라 할 때 이를 A의 수학적 확률이라 한다.
2) 한 사건 A가 일어날 확률을 P(A)라 할 때 N번의 반복시행에서 사건 A가 일어난 횟수를 R이라 하면, 상대도수 R/N은 N이 커짐에 따라 확률 P(A)에 가까워짐을 알 수 있다. P(A)를 사건 A의 통계적 확률이라 한다.
3) 두 사건 A,B가 독립일 때 사건 B의 확률은 A가 일어났다는 가정 하에서의 B의 조건부 확률과는 다르다.
4) 표본공간에서 임의의 사건 A가 일어날 확률 P(A)는 항상 0과 1사이에 있다.
독립사건 : A의 발생이 B가 발생할 확률을 바꾸지 않는 사건
두사건 A,B가 독립이면 P(B/A)=P(B)이다
조건부확률 : 사건 B가 발생했다는 조건 아래서 사건 A가 발생할 조건부 확률이다.
조건부확률에서 P(A|B) = P(A∩B) / P(B), 단 P(B) > 0
29. TV광고수에 따른 Sales에 대한 산점도이다. 이에 대한 설명으로 알맞지 않은 것은?

1) TV광고가 증가 할수록 Sales도 증가하는 경향이 있다.
2) TV광고와 Sales는 양의 상관과계를 가진다.
3) TV광고가 증가할 수록 Sales의 분산은 동일하다.
4) Sales를 설명하기 위해 TV광고를 독립변수로 하는 단순선형회귀모델은 적절하다.
Salary의 경우 Median < Mean이므로 오른쪽으로 꼬리가 긴 분포이다.
Mean : 평균값 : 데이터의 총합을 데이터의 개수로 나눈 값으로, 데이터 집합의 모든 값을 고려합니다. 예를 들어, {1, 2, 3, 4, 5}의 평균값은 (1+2+3+4+5)/5 = 3입니다. 평균값은 극단값에 영향을 받을 수 있습니다.
Median : 중앙값 : 데이터를 작은 순서대로 정렬하여 가운데에 위치한 값을 의미합니다. 예를 들어, {1, 2, 3, 4, 5}에서 중간값은 3입니다. 이는 극단값에 큰 영향을 받지 않습니다.
단순선형회귀모델은 하나의 독립 변수와 하나의 종속 변수 간의 선형 관계를 모델링하는 회귀 분석 기법입니다. 이 모델은 데이터의 패턴을 설명하고 예측하는 데 사용됩니다. 단순선형회귀모델에서, 독립 변수는 종속 변수에 대한 예측에 사용되며, 이러한 변수 간의 관계는 직선 형태로 가정됩니다.
이 모델은 다음과 같은 가정에 기초합니다:
독립 변수와 종속 변수 사이에는 선형 관계가 있습니다.
잔차(예측 값과 실제 값 사이의 차이)는 정규 분포를 따릅니다.
잔차의 분산은 독립 변수와 관계없이 일정합니다.
이 모델은 주로 회귀 분석에서 사용되며, 예를 들어 기온과 판매량 사이의 관계, 광고 비용과 매출 사이의 관계 등을 조사할 때 적용됩니다.
30. Hitters dataset의 일부이다. 다음 설명 중 적절하지 않은것은?
> summary(Hitters)
AtBat Hits HmRun NewLeague Salary
Min. : 16.0 Min. : 1 Min. : 0.00 A:176 Min. : 67.5
1st Qu. :255.2 1st Qu. : 64 1st Qu. : 4.00 N:146 1st Qu. : 190.0
Median :379.5 Median : 96 Median : 8.00 Median : 425.0
Mean :380.9 Mean :101 Mean :10.77 Mean : 535.9
3rd Qu. :512.0 3rd Qu.:137 3rd Qu.:16.00 3rd Qu. : 750.0
Max. :687.0 Max. :238 Max. :40.00 Max. :2460.0
NA's :59
1) Salary 변수 분포는 왼쪽꼬리가 긴 분포를 가진다.
2) NewLeague 변수는 범주형 자료이다.
3) Hits 변수에는 결측값이 없음을 알 수 있다.
4) HmRun 변수의 최대값은 40이다.
Salary의 경우 Median < Mean 이므로 오른쪽으로 꼬리가 긴 분포이다.
31. 모집단의 크기가 비교적 작을 때 주로 사용되며 한번 추출된 표본의 재추출될 수 있는 표본 추출 방법은 무엇인가?
1) 복원추출법
2) 층화추출법
3) 군집추출법
4) 계층추출법
1) 복원추출법: 복원추출법은 표본을 추출할 때 표본이 추출된 후 다시 모집단에 반환되어 다시 추출될 수 있는 방법을 말합니다. 이 방법은 각 표본이 독립적으로 추출되며, 동일한 표본이 여러 번 추출될 수 있다는 특징을 가지고 있습니다. 이 방법은 큰 모집단에서 상대적으로 작은 표본을 추출할 때 유용합니다.
2) 층화추출법: 층화추출법은 모집단을 여러 층(strata)으로 나눈 후 각 층에서 표본을 추출하는 방법입니다. 이 방법은 모집단 내의 다양한 특성을 고려하여 표본을 추출함으로써 추출 편향을 줄이고 표본의 대표성을 높일 수 있습니다.
3) 군집추출법: 군집추출법은 모집단을 비슷한 특성을 가진 군집(cluster)으로 나눈 후 몇 개의 군집을 무작위로 선택하여 해당 군집 내의 모든 개체를 표본으로 선택하는 방법입니다. 이 방법은 표본 추출의 효율성을 높일 수 있으며, 모집단이 군집화되어 있는 경우 유용합니다.
4) 계층추출법: 계층추출법은 모집단을 서로 겹치지 않는 여러 개의 계층(strata)으로 나눈 후 각 계층에서 무작위로 표본을 추출하는 방법입니다. 이 방법은 층화추출법과 유사하지만, 각 계층의 크기에 따라 가중치를 부여하여 표본을 추출하는 특징이 있습니다.
32. 닭 사료의 종류(feed)와 닭의 성장에 대한 boxplot결과이다. 옳지 않은 것은?

1) 이상치가 존재하지 않는 것을 알 수 있다.
2) casein의 경우 horsebean 보다 중위수가 크다.
3) soybean의 경우 meatmeal 보다 최소값은 크고, 최대값이 작다.
4) horsebean 사료를 먹은 닭의 무게가 가장 작은 쪽에 분포해 있다.
sunflower의 경우 이상치가 존재한다.
33. 자료의 척도에 대한 설명으로 부적절한 것은?
1) 명목척도 : 단순히 측정 대상의 특성을 분류하거나 확인하기 위한 목적으로 사용한다.
2) 서열척도 : 대소 또는 높고 낮음 등의 순위만 제공할 뿐 양적인 비교는 할 수 없다.
3) 등간척도 : 사칙연산이 가능하다.
4) 비율척도 : 절대 0점이 존재하여 측정값 사이의 비율 계산이 가능한 척도이다.
3) 등간척도(구간척도) : 순위를 부여하되 순위 사이의 간격이 동일하여 양적인 비교가 가능(덧셈, 뺄셈 가능), 절대 0점이 존재하지 않음(온도계 수치, 물가지수)
4) 비율척도(Ratio scale) : 절대 0점이 존재하되 측정값 사이의 비율 계산이 가능한 척도로 사칙연산이 가능하다.
- 명목척도: 명목척도는 가장 기본적인 척도로, 개체를 분류하거나 식별하기 위해 사용됩니다. 이러한 분류는 서로 배타적이며, 순서나 크기의 의미가 없습니다. 예를 들어, 성별, 종교, 혈액형 등이 명목척도에 속합니다.
- 서열척도: 서열척도는 명목척도보다 조금 더 발전된 형태로, 항목 간의 상대적 순서나 위치를 나타냅니다. 이 척도에서는 항목들 간의 상대적인 위치를 알 수 있지만, 간격이나 비율의 의미는 없습니다. 예를 들어, 학생들의 성적순위나 설문조사에서의 선호도 순위 등이 서열척도에 해당됩니다.
- 등간척도: 등간척도는 명목척도와 서열척도의 특성을 모두 가지고 있으며, 각 항목 사이의 간격이 일정하고 구분되어 있습니다. 즉, 항목 간의 상대적 위치 뿐만 아니라 간격도 의미가 있는 척도입니다. 예를 들어, 온도를 측정하는 것이 등간척도에 해당됩니다. 20도와 30도 사이의 간격은 30도와 40도 사이의 간격과 동일하게 해석됩니다.
- 비율척도: 비율척도는 가장 발전된 형태의 척도로, 등간척도의 특성에 더하여 각 항목 사이의 비율이 의미가 있는 척도입니다. 즉, 절대적인 영점이 존재하고, 비율 연산이 가능합니다. 예를 들어, 길이, 무게, 시간 등을 측정하는 것이 비율척도에 해당됩니다. 예를 들어, 20cm의 길이는 10cm의 두 배이며, 40cm의 절반이 됩니다.


34. 연관분석에 대한 설명 중 잘못된 것은?
1) 비목적성 분석기법으로 계산이 간편하다.
2) 대표적인 알고리즘으로 Aprior가 있다.
3) 조건반응으로 표현되는 연관분석의 결과를 이해하기 쉽다.
4) 품목 수가 증가해도 분석에 필요한 계산이 늘어나지 않는다.
| 연관분석의 장점 | 연관분석의 단점 |
| - 조건반응(if-then)으로 표현되는 연관 분석의 결과를 이해하기 쉽다. - 강력한 비목적성 분석기법이며, 분석계산이 간편하다. |
- 분석 품목 수가 증가하면, 분석 계산이 기하급수적으로 증가 - 너무 세분화된 품목을 가지고 연관규칙을 찾으려면 의미없는 분석결과가 도출됨. - 상대적 거래량이 적으면 규칙 발견 시 제외되기 어려움. |
35. 데이터 분할에 대한 설명 중 틀린 것은?
1) 데이터마이닝 적용 후 결과의 신빙성 검증을 위해 데이터를 학습, 검증, 테스트 데이터로 나누어 사용한다.
2) 검증용 데이터는 모델 성능 평가에 사용한다.
3) 테스트용 데이터와 학습 데이터는 섞여서는 안된다.
4) 검증용 데이터는 학습 단계에서 사용된다.
홀드아웃(Hold out)
- Training Data : 학습용 데이터
- Test Data : 학습 종료 후 성능 확인(모델평가)용 데이터
- Validation Data : 학습단계에서 사용되며, 학습 중 성능확인용 데이터(Overfitting여부확인, Early stopping 등을 위해 사용)
Validation Data은 머신러닝 및 데이터 분석에서 중요한 개념입니다. 이는 모델의 성능을 평가하기 위해 사용되는 데이터 집합입니다. 주로 모델을 훈련시키는 데 사용되는 학습 데이터와는 별도로 사용됩니다.
36. 표준오차에 대한 설명 중 틀린 것은?
1) 표본평균이 모평균과 얼마나 떨어져 있는가를 나타낸다.
2) 표준오차는 σ/√𝒏 로 구한다.
3) 표준오차 95%는 신뢰구간에 모수의 참값이 포함되어 있음을 나타낸다.
4) 더 작은 표준 오차는 추정차가 모집단 파라미터를 더 정확하게 반영한다는 것을 나타낸다.
표준오차
- 표본 집단의 평균값이 실제 모집단의 평균값과 얼마나 차이가 있는디 나타냄.
- 모집단에서 샘플을 무한번 뽑아서 각 샘플마다 평균을 구했을 때, 그 평균의 표준편차를 말함
- 표준평균이 모평균과 얼마나 떨어져 있는가를 나타냄, 𝒏이 클수록 작은 값
- SE(Standard error) = (원시데이터의 표준편차)/√(평균값 계산에 사용한 데이터 수) = σ/√𝒏 ≈ 𝒔/√𝒏
* 신뢰수준 95%는 샘플을 랜덤하게 100번 추출해서 이중에 95번이 신뢰구간에 모수의 참 값이 포함되어 있음을 나타낸다.
37. 아래의 분순도 측정결과를 사용해서 구한 지니지수는 얼마인가?
◆ ● ● ● ●
1) 0.5
2) 0.32
3) 0.48
4) 0.38

지니지수 식 :
1 - ∑(각 범주별수/전체수 )^2
= 1 – ((1/5)^2 + (4/5)^ 2 )
= 1 - (1/25 + 16/25) = 8/25 = 0.32

38. 어떤 슈퍼마켓 고객 6명의 장바구니별 구입품목이 다음과 같을 때, 연관 규칙(콜라->맥주)의 지지도는?
거래번호 판매상품
---------------------
1 소주, 콜라, 맥주
2 소주, 콜라, 와인
3 소주, 주스
4 콜라, 맥주
5 소주, 콜라, 맥주, 와인
6 주스
콜라를 고른 사람이 맥주도 고른다.
지지도 = A와 B가 동시에 포함된 수 / 전체 거래수
39. 다음의 품목/거래량 표를 사용하여 연관규칙(딸기->사과)향상도는 무엇인가?
품목 거래량
------------------------
딸기, 사과, 포도 100
딸기, 포도 400
사과, 포도, 바나나 150
사과, 딸기, 바나나 200
포도, 바나나 150
1) 0.3
2) 0.3/(0.7*0.45)
3) 0.3/07
4) 0.3/(0.7+0.45)
- 향상도 : A가 주어지지 않았을 때 B의 확률 대비 A가 주어졌을 때 B의 확률 증가 비율
- 품목 B를 구매한 고객 대비 품목 A를 구매한 후 품목 B를 구매하는 고객에 대한 확률
- 향상도 =P(B|A)/P(B) = P(A∩B) / (P(A)*P(B))
- A = 딸기 , B = 사과
향상도 = (0.3) / (0.7* 0.45)
40. 다음 설명에 해당하는 앙상블 기법은?
[설명]
여러 개의 붓스트랩 자료를 생성하고 각 붓스트랩 자료에 예측 모형을 만든 후
결합하여 최종 예측 모형을 만드는 방법
1) Bagging
2) Voting
3) Boosting
4) Stacking
2) 보팅(Voting) : 서로 다른 여러 개의 모형을 생성하고 결과를 집계하여 많은 표를 받은 것을 답으로 하는 방식
3) 부스팅(Boosting) : 순차하는 학습, 붓스트랩 표본을 구성하는 재표본 과정에서 분류가 잘못된 데이터에 더 큰 가중치를 주어 표본을 추출하는 기법
4) 스태킹(Stacking) : 두 단계의 학습을 사용하는 방식으로 서로 다른 여러 모형의 예측 결과를 다시 학습데이터로 하는 모형을 사용함.
41. 군집분석 관련 설명으로 틀린 것은?
1) 계층적 군집분석은 사전에 군집 수 k를 설정할 필요가 없는 탐색적 모형이다.
2) 집단간 이질화, 집단내 동질화 모두 낮은 것을 군집으로 선택한다.
3) K-means 군집은 잡음이나 이상값에 영향을 받기 쉽다.
4) 군집분석은 비지도학습이다.
- 집단간 이질화, 집단내 동질화가 모두 높은 것을 군집으로 선택한다.
42. 신경망 노드 중 무작위로 노드를 선정하여 다수의 모형을 구성하고 학습한 뒤 각 모형의 결과를 결합해 분류 및 예측하는 기법을 무엇이라고 하는가?
1) Mini-Batch
2) Bagging
3) Drop-out
4) AdaBoost
1) Mini-Batch : 단위 별로 쪼개서 학습하는 것으로 데이터를 일정한 크기로 나누어 모형을 구성함.
2) Bagging : 무작위 노드 선정이 아닌 Boostrap방식으로 노드를 선정하는 방법을 사용
3) Drop-out : 딥러닝에서 과대적합 방지를 위해 노드의 일부를 랜덤하게 학습하지 못하게 하는 기법
4) AdaBoost : 강한 분류기를 약한 분류기로 학습시키는 앙상블 방법으로, 각 모델은 이전 모델의 에러를 보완하도록 가중치를 조절하면서 순차적으로 학습된다. 이 때 각 모델은 이전 모델이 잘못 분류한 샘플에 집중하여 학습
43. 회귀분석의 결과 해석으로 틀린 것은?
> library(MASS)
> data(ChickWeight)
> Chick = ChickWeight[ChickWeight$Diet==1 & ChickWeight$Chick==1,]
> model = lm(weight ~ Time, Chick)
> summary(model)
Call:
lm(formula = weight ~ Time, data = Chick)
Residuals:
Min 1Q Median 3Q Max
-14.3202 -11.3081 -0.3444 11.1162 17.5346
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24.4654 6.7279 3.636 0.00456 **
Time 7.9879 0.5236 15.255 2.97e-08 ***
---
Signif. codes: 0 '***' 0.001 '***' 0.01 '*' 0.05 ',' 0.1 ' ' 1
Residual standard error: 12.29 on 10 degrees of freedom
Multiple R-squared: 0.9588, Adjusted R-squared: 0.9547
F-statistic: 232.7 on 1 and 10 DF, p-value: 2.974e-08
1) 결정계수는 0.9588이다
2) 5% 유의수준에서 모형은 통계적으로 유의미하다.
3) Time이 1단위 증가하면 Weight가 평균적으로 8.8 증가한다.
4) 추정된 회귀식은 weight=24.4654 + 7.9879 * Time이다.
추정된 회귀식은 weight=24.4654 + 7.9879 * Time이므로 Time이 1단위 증가하면 weight가 평균적으로 7.9879 증가한다.
확실히 도와드릴 수 있습니다! 위 코드는 R 프로그램에서 닭의 무게 데이터를 분석하고 결과를 요약하는 내용입니다. 빅데이터 분석 초보자이신 님께 알려드려야 할 정보는 다음과 같습니다.
**1. 패키지 로딩 (library(MASS))**
- 이 코드는 `MASS` 패키지를 로딩하는 명령어입니다. R 프로그램에서 특정 기능을 사용하기 위해서는 패키지를 로딩해야 합니다.
- `MASS` 패키지는 통계 분석에 사용되는 다양한 함수를 제공합니다.
**2. 데이터 불러오기 (data(ChickWeight))**
- 이 코드는 `ChickWeight`라는 데이터 세트를 불러오는 명령어입니다.
- R 프로그램에는 기본적으로 여러 가지 예시 데이터 세트가 포함되어 있으며 `data()` 함수를 이용하여 불러올 수 있습니다.
- 이 경우 불러온 데이터는 `ChickWeight` 객체에 저장됩니다.
**3. 데이터 필터링 (Chick[ChickWeight$Diet==1 & ChickWeight$Chick==1,])**
- 이 코드는 원본 데이터에서 특정 조건에 맞는 데이터만 추출하는 작업입니다.
- `ChickWeight$Diet == 1` : 사료 종류가 1인 것만 선택
- `ChickWeight$Chick == 1` : 병아리 번호가 1인 것만 선택
- 필터링된 데이터는 새로운 `Chick` 객체에 저장됩니다.
**4. 선형 회귀 분석 (model = lm(weight ~ Time, data = Chick))**
- 이 코드는 선형 회귀 분석을 수행하는 명령어입니다.
- `lm` 함수는 선형 회귀 모델을 생성합니다.
- `weight ~ Time` : 종속변수(weight)가 독립변수(Time)에 의해 선형적으로 영향을 받는다는 가정을 나타냄
- `data = Chick` : 분석에 사용할 데이터 세트를 지정
**5. 요약 정보 (summary(model))**
- `summary(model)` 코드는 선형 회귀 분석 결과를 요약하여 출력합니다. 출력 결과를 살펴보면 다음과 같은 정보를 얻을 수 있습니다.
* **회귀 계수 (Coefficients)**
- (Intercept) : y 절편 값 (weight의 평균값)
- Time : 기울기 (weight가 Time 변화에 따라 얼마나 증가하는지)
* **모형의 유의성 검정 (Signif. codes)**
- 코드 별로 *** 표시는 해당 변수의 영향력이 유의미하다는 것을 나타냄
- 본 예시에서는 (Intercept)과 Time 모두 유의미한 영향을 미친다는 결론을 내릴 수 있음
* **잔차 분산 분석 (Residuals)**
- 모델에 의해 설명되지 않은 오차의 정도를 나타냄
* **R-제곱 (R-squared)**
- 결정 계수라고도 불림. 모델의 설명력을 나타내는 지표 (0~1 사이 값, 1に近いほど 설명력이 좋음)
- 본 예시에서는 모델이 전체 변동의 95.88%를 설명한다는 것을 알 수 있음
* **F 검정 (F-statistic)**
- 전체 모형의 유의성을 검정하는 지표. p-value이 작을수록 모형이 유의미하다는 것을 의미
**6. 결론**
위 코드를 통해 사료 종류가 1이고 병아리 번호가 1인 데이터에 대해 が生후 시간 (Time)이 증가함에 따라 체중 (weight)이 유의미하게 증가하는 선형 관계가 있음을 알 수 있습니다.
물론 이 코드는 간단한 예시이며, 빅데이터 분석에서는 보다 복잡한 데이터와 모델을 다루게 됩니다. 하지만 기본적인 분석 과정을 이해하는 것은 빅데이터 분석을 배우는데 중요한 첫걸음입니다.
44. 아래 설명에 해당하는 정답을 고르시오.
[설명]
독립변수간 상관관계가 높아 많은 문제점을 발생하는 현상으로 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들게 되는 것을 다중공선성이라고 한다. 이것의 해결 방법으로 사용할 수 있는 것은 무엇인가?
1) 주성분 분석
2) 교차 분석
3) 오차 분석
4) 연관 분석
다중 공선성
- 모형의 일부 설명변수(=예측변수)가 다른 설명변수와 상관되어 있을 때 발생하는 조건
- 중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 됨.
주성분 분석
- 주성분분석은 비지도학습으로 회귀분석의 다중공선성 문제 해결을 위해 사용한다.
- 차원 축소, 이상치 탐지, 자료의 그룹화에 사용할 수 있다.
- 주성분분석은 목표변수를 고려해 목표변수를 잘 예측/분류할 수 있는 선형결합으로 이루어진 몇 개의 주성분을 찾아내기 위한 것이다.
45. 아래 설명의 답을 작성하시오.
[설명]
시계열분석에게 시계열의 수준과 분산에 체계적인 변화가 없고, 주기적 변동이 없다는 것으로 미래는 확률적으로 과거와 동일하다는 것을 의미하는 용어는?
정상성
46. 다음 오분류표를 사용하여 F1 Score를 구하시오.
| 오분류표 | 예측값 | ||
| TRUE | FALSE | ||
| 실제값 | TRUE | 15(TP) | 60(FN) |
| FALSE | 60(FP) | 30(TN) | |
1/5
F1 Score는 일반적으로 정밀도(Precision)와 재현율(Recall)을 사용하여 계산하지만, 오분류표(Confusion Matrix)를 사용하여 계산하는 방법도 있습니다.
오분류표를 이용한 F1 Score 계산 공식:
F1 Score = 2 *(정확도*재현율)/(정확도+재현율)
정확도(Precision)=TP / TP + FP=15/75=1/5
재현율(Recall)=TP / TP + FN=15/75=1/5
특이도(Specifity)=TN / TN + FP=30/60+30=1/3
F1 Score = 2 * (TP / (TP + FP)) * (TP / (TP + FN)) / ((TP / (TP + FP)) + (TP / (TP + FN)))
2*(0.2*0.2/0.2+0.2)=1/5
변수:
TP (True Positive): 실제로 양성이고 모델이 양성으로 예측한 경우
FP (False Positive): 실제로 음성인데 모델이 양성으로 예측한 경우
TN (True Negative): 실제로 음성이고 모델이 음성으로 예측한 경우
FN (False Negative): 실제로 양성인데 모델이 음성으로 예측한 경우
47. 다음 빈칸에 알맞은 단어를 작성하시오.
완전 연결법이라고도 하며, 두 군집 사이의 거리를 군집에서 하나씩 관측 값을 뽑았을 때 나타날 수 있는 거리의 ( )을 측정한다.
최댓값
최단연결법 : 단일연결법이라고도 하며, 두 군집 사이의 거리를 군집에서 하나씩 관측 값을 뽑았을 때 나타날 수 있는 거리의 최솟값을 측정한다.
최장연결법(완전연결법) : 두 군집 사이의 거리를 군집에서 하나씩 관측 값을 뽑았을 때 나타날 수 있는 거리의 최대값을 측정한다.
48. 주성분 분석 결과에서 주성분 1개를 사용했을 때 분산을 구하시오.(소수점 둘째 자리에서 반올림)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6
Standard deviation(표준편차) 1.8118 1.0042 0.9057 0.7771 0.52403 2.525e-16
Proportion of Variance(분산비율) 0.5746 0.1423 0.1367 0.1007 0.04577 0.000e+00
Cumulative Proportion(누적비율) 0.5746 0.7169 0.8536 0.9542 1.00000 1.000e+00
57.5%
주성분1개를 사용했을 때의 분산은 PC1의 Proportion of Variance를 보고 판단할 수 있다.
49. 아래 설명의 답을 작성하시오.
[설명]
생물학적 진화 과정을 모방하여 최적화 및 검색 문제를 해결하는데 사용되는 게산 알고리즘으로 다양한 해를 탐색하고 선택, 교차, 변이와 같은 유전 연산을 통해 최적의 해를 찾아내는데 효과적인 알고리즘은?
유전 알고리즘.
50. 아래 설명의 답을 작성하시오.
[설명]
모집단을 먼저 서로 겹치지 않는 여러 개의 층으로 분할한 후, 각 층에서 단순 임의 추출법에 따라 배정된 표본을 추출하는 방법은?
층화추출법
단순 무작위 추출법 : 모 집단의 각 개체의 표본으로 선택될 확률이 동일하게 추출되는 겨우
군집 추출법 : 모집단을 차이가 없는 여러 개의 집단(Cluster)로 나누고, 이들 집단 중 몇 개를 선택한 후, 선택된 집단 내에서 필요한 만큼의 표본을 임의로 선택함.
계통 추출법 : 모집단 개체에 1,2,.... N이라는 일련번호를 부여한 후, 첫 번째 표본을 임의로 선택하고 일정 간격으로 다음 표본을 선택함.
https://yunamom.tistory.com/371#a1
[ADsP] 제38회 기출문제 ( 50문제 / 정답 )
📖ADsP. 제 38 회 기출 문제 문제 1. 데이터베이스의 구성요소에 대한 설명이다. 각각 무엇에 대한 설명인가? 정답확인 가. 데이터를 설명해주는 데이터로 데이터의 특성, 구조, 정의 및 관리 정보
yunamom.tistory.com
'국가자격증(큐넷) > ADsP 데이터분석준전문가' 카테고리의 다른 글
| ADsP데이터분석준전문가 2024 나름내용정리 (0) | 2024.04.21 |
|---|---|
| ADsP 2시간 정복 (1) | 2024.04.20 |
| 데이터분석준전문가(ADsP) 40회 기출문제풀이 (0) | 2024.04.16 |
| adsp 기출문제 (0) | 2024.04.11 |
| ADsP 데이터분석준전문가, 고사장위치(2023년 1월기준) (0) | 2024.03.26 |