01. 다음 중 기업의 전략 도출을 위한 가치 기반 분석과 관련된 설명으로 옳지 않은 것은?
1) 핵심적인 비즈니스 이슈에 답을 주는 분석은 기업의 경쟁전략과 밀접하게 연관된다.
2) 다양한 대량의 데이터를 수집, 분석하여 새로운 정보나 인사이트를 도출하고,
이를 기반으로 비즈니스 가치를 창출하는 것이 중요하다.
3) 전략적 분석과 통찰력의 창출은 빅데이터 프로젝트에서 핵심적일 역할을 한다.
4) 기존 성과를 유지하고 업계를 따라잡는 것이 전략적 가치 기반 분석의 가장 중요한 역할이다.
02. 빅데이터 분석 활용의 효과 예시로 가장 옳지 않은 것은?
1) 운송 비용의 절감
2) 상품 개발과 조립 비용의 절감
3) 서비스 산업의 확대와 제조업의 축소
4) 새로운 수익원의 발굴 및 활용
03. 데이터베이스의 일반적인 특징으로 옳지 않은 것은?
1) 데이터베이스는 다수가 공동으로 이용하는 공용 데이터이다.
2) 데이터베이스는 응용프로그램의 종속성을 가진다.
3) 데이터베이스는 컴퓨터가 접근 가능한 저장매체에 데이터를 저장한다.
4) 데이터베이스는 동일한 내용의 데이터가 중복되지 않는 통합 데이터이다.
통합된 (Intergrated) 데이터 : 동일한 내용의 데이터가 중복되어 있지 않다.
저장된(Stored) 데이터 : 컴퓨터 매체가 접근할 수 있는 저장 매체에 저장되어 있다.
공용(Shared) 데이터 : 여러 사용자가 공유할 수 있다.
변화하는(Operational) 데이터 : 삽입, 수정, 삭제를 통해 항상 최신의 정확한 데이터를 유지해야 한다.
04. 다음중 기업 내부 데이터베이스 솔루션으로 알맞지 않은 것은?
1) ERP
2) ITS
3) SCM
4) CRM
ERP (Enterprise Resource Planning, 기업자원관리시스템):
기능: 재무, 인사, 재고, 생산 등 기업 전체의 자원을 통합 관리하는 시스템입니다.
목표: 서로 다른 부서간의 정보 공유를 통해 효율성 증대, 비용 절감, 의사 결정 지원 등을 목표로 합니다.
예시: 주문 처리 시 재고 확인, 재무 승인, 생산 계획 수립 등을 ERP 시스템을 통해 연동하여 진행
ITS ( Intelligent Transport Systems , 지능형교통체계):
지능형교통체계는 교통시설의 이용을 극대화하고 교통수단의 수송효율을 높이는 한편, 국민의 교통편의 증진과 교통안전을 도모할 수 있도록 교통체계의 운영ㆍ관리를 자동화ㆍ과학화하는 체계로서 도로ㆍ철도ㆍ공항 등 교통시설과 자동차ㆍ열차 등 교통수단 등 교통체계 구성요소에 교통ㆍ전자ㆍ통신ㆍ제어 등 첨단기술을 적용하여 교통시설ㆍ수단의 실시간 관리ㆍ제어와 교통정보의 실시간 수집ㆍ활용하는 환경 친화적 미래형 교통체계
SCM (Supply Chain Management, 공급망관리시스템):
기능: 원자재 조달부터 제품 생산, 물류, 판매까지 공급망 전체를 관리하는 시스템입니다.
목표: 재고 최적화, 물류비 절감, 공급망 가시성 (visibility) 향상 등을 통해 공급망 효율성을 개선하는 것이 목표입니다.
예시: 원자재 발주 관리, 생산 계획 수립, 물류 창고 관리, 수요 예측 등을 통합하여 공급망 전 과정을 최적화
CRM (Customer Relationship Management, 고객관리시스템):
기능: 고객 정보, 영업 활동, 마케팅 캠페인 등 고객과 관련된 모든 정보를 관리하는 시스템입니다.
목표: 고객 만족도 향상, 로열티 제고, 판매 증대 등을 위해 고객과의 관계를 발전시키는 것이 목표입니다.
예시: 고객 문의 관리, 영업 기회 추적, 마케팅 캠페인 수행 결과 분석, 고객 구매 이력 분석 등을 통해 고객 관계 유지 및 강화
05. 데이터의 특징에 대한 설명 중 옳지 않는 것은?
1) 데이터는 객관적 사실이다.
2) 데이터는 추론과 추정의 근거를 이루는 사실이다.
3) 데이터의 최소단위는 바이트로 0과 1의 이진수 하나로 이루어져 있다.
4) 단순한 객체로서의 가치와 다른 객체와의 상호 관계 속에서의 가치를 갖는다.
BIT : 0과 1의 최소단위
BYTE : 8BIT
WORD : 컴퓨터에서 연산의 기본 단위가 되는 정보의 양
06. 이미지, 로그, 영상, 텍스트 등의 데이터 형태로 알맞은 것은?
1) Structured data
2) Quantitative data
3) Unstructured data
4) Semi-structured data
1. 구조적 데이터 (Structured data)
정의: 규칙적인 형식으로 구성되어 데이터베이스에 쉽게 저장하고 분석 가능한 데이터입니다. 행과 열로 구성된 표 형태로 저장되며, 각 열은 특정 속성을 나타내고 각 행은 단일 레코드 또는 데이터 포인트를 나타냅니다.
예시:
스프레드시트에 저장된 고객 정보 (이름, 주소, 전화번호)
금융 거래 (날짜, 금액, 계좌 번호)
센서 측정값 (시간, 온도, 압력)
2. 수치적 데이터 (Quantitative data)
정의: 숫자로 표현되고 계산 또는 측정 가능한 데이터입니다.
이산 데이터 (Discrete data): 명확한 값을 나타내고 종종 정수 형태로 나타납니다 (예: 고객 수, 시험 점수).
연속 데이터 (Continuous data): 값 범위를 나타내고 소수점 형태로 표현될 수 있습니다 (예: 키, 체중, 온도).
참고: 수치적 데이터는 구조적 데이터의 일부일 수 있지만 (예: 데이터베이스의 제품 가격), 모든 구조적 데이터가 수치적이지는 않습니다 (예: 고객 이름).
3. 비구조적 데이터 (Unstructured data)
정의: 규칙적인 형식이 없고 기존 데이터 분석 도구로 직접 분석하기 어려운 데이터입니다. 인간이 생성하는 경우가 많으며 텍스트, 이미지, 오디오, 비디오를 포함합니다.
예시:
소셜 미디어 게시물
이메일 및 문서
이미지 및 비디오
미리 처리되지 않은 센서 데이터 스트림
4. 준구조적 데이터 (Semi-structured data)
정의: 구조적 데이터와 비구조적 데이터 사이에 위치하는 데이터입니다. 일부 내부 조직은 있지만 관계형 데이터베이스와 같은 엄격한 스키마를 따르지는 않습니다. 종종 태그 또는 마커를 사용하여 데이터 요소를 부분적으로 정의합니다.
예시:
JSON(JavaScript Object Notation) 파일: 애플리케이션 간 데이터 교환에 사용됩니다.
XML(Extensible Markup Language) 파일: 구성 설정 또는 데이터 교환에 사용됩니다.
타임스탬프, 사용자 작업 및 오류 메시지를 포함할 수 있는 로그 파일
이미지 또는 첨부 파일이 포함된 이메일
07. 빅데이터 활용 기법에 관한 설명으로 옳지 않은 것은?
1) 군집분석을 통해 고객의 개인신용평가에 활용한다.(신용예측에 활용한다.)
2) 최적화 문제에 대한 해결방안으로 사용되는 빅데이터 분석은 유전알고리즘이다.
3) 특정 주제에 대해 사용되는 텍스트를 분석하는 것을 감정(성)분석이라 한다.
4) 최근 핀테크 기업들은 사회연결망분석을 활용하고 있다.
08. 빅데이터가 만들어낸 본질적인 변화로 옳지 않은 것은?
가. 사전처리 -> 사후처리
나. 대면조사 -> 표본조사
다. 질보다 -> 양적으로
라. 상관관계 -> 인과관계
1) 가, 나
2) 나, 라
3) 다, 라
4) 가, 라
사전 -> 사후
표본 -> 전수
질 -> 양
인과 -> 상관
09. 가트너가 본 데이터 사이언티스트의 요구 역량으로 알맞지 않은 것은?
1) 데이터 관리
2) 분석모델링
3) 비즈니스 분석
4) 조직관리
데이터 사이언티스트 (Data Scientist)는 데이터를 수집, 정제, 분석, 시각화하여 비즈니스 문제 해결에 도움을 주는 전문가입니다. 다양한 분야에서 활동하며, 기업의 성장과 발전에 중요한 역할을 수행합니다.
데이터 사이언티스트의 주요 활동:
데이터 수집 및 정제: 다양한 출처에서 데이터를 수집하고, 분석에 적합하도록 정제합니다.
탐색적 데이터 분석 (EDA): 데이터의 특성을 파악하고, 시각화하여 패턴을 찾습니다.
모델링: 데이터를 기반으로 예측 모델을 개발하고 평가합니다.
머신러닝: 머신러닝 알고리즘을 사용하여 데이터로부터 자동으로 학습하고 예측합니다.
인공지능: 인공지능 기술을 활용하여 데이터 분석을 자동화하고, 더 나은 결과를 도출합니다.
데이터 시각화: 분석 결과를 시각적으로 표현하여 이해를 돕습니다.
소통: 분석 결과를 비즈니스 이해관계자에게 명확하고 효과적으로 전달합니다.
데이터 사이언티스트의 역할:
데이터 기반 의사 결정 지원: 데이터 분석 결과를 바탕으로 비즈니스 전략 수립 및 의사 결정을 지원합니다.
고객 이해: 고객 데이터를 분석하여 고객 니즈와 행동을 파악하고, 이를 바탕으로 마케팅 전략 개발, 제품 개선 등을 지원합니다.
운영 효율성 향상: 생산, 물류, 재고 관리 등의 운영 데이터를 분석하여 비용 절감, 생산성 향상, 품질 관리 등을 지원합니다.
새로운 기회 발굴: 데이터 분석을 통해 새로운 시장 트렌드를 발견하고, 이를 활용하여 새로운 사업 기회를 발굴합니다.
위험 관리: 금융 데이터, 리스크 데이터 등을 분석하여 위험 요소를 파악하고, 이를 최소화하기 위한 전략을 수립합니다.
10. 데이터 사이언티스트에게 요구되는 하드스킬로 알맞은 것은?
1) 데이터 분석 기술
2) 시각화를 활용한 설득력
3) 커뮤니케이션 기술
4) 창의적 사고
| 하드스킬 | 소프트스킬 |
| 데이터 분석을 위한 기술과 지식 | 데이터 사이언티스트가 비즈니스 환경에서 효과적으로 업무를 수행하기 위한 역량 |
| 통계 및 수학 지식 프로그래밍 언어(R, Python, SQL 등) 머신러닝 알고리즘 데이터 시각화 데이터베이스 클라우드 컴퓨팅 |
비즈니스 이해도 문제 정의 능력 문제 해결 능력 창의적 사고력 협업 능력 커뮤니케이션 능력 학습 능력 |
2. 데이터 분석 기획
11. 조직에 데이터 분석 문화를 자리잡게 하기 위한 행동으로 알맞지 않은 것은?
1) 경영진이 데이터에 기반한 의사결정을 할 수 있는 기업문화 정착의 변화관리를 지속해야 한다.
2) 분석적인 사고를 업무에 적용할 수 있도록 다양한 교육을 실시해야 한다.
3) 단순한 도구(Tool) 교육이 아닌 분석역량의 확보와 강화에 초점을 맞춰야 한다.
4) 경영진을 대상으로 한시적 속성교육을 강화해야 한다.
12. 아래에서 설명한 데이터 분석구조는?
- 전사 분석업무를 별도의 분석 전담 조직에서 담당
- 전랴적 중요도에 따라 분석조직이 우선순위를 정해서 진행 가능
- 현업 업무버서의 분석업무와 이중화/이원화 가능성 높음
1) 집중구조
2) 기능구조
3) 확산구조
4) 분산 구조
집중 구조: 데이터가 하나의 중앙 저장소에 저장됩니다. 이 구조는 데이터 관리가 간편하지만, 데이터 볼륨이 커지면 성능 저하가 발생할 수 있습니다.
기능 구조: 데이터가 분석 목적에 따라 여러 저장소에 분산됩니다. 이 구조는 특정 분석 작업에 대한 성능을 향상시킬 수 있지만, 데이터 관리가 복잡해질 수 있습니다.
확산 구조: 데이터가 여러 노드에 분산됩니다. 이 구조는 대규모 데이터 세트를 처리하는 데 유용하지만, 데이터 일관성 유지가 어려울 수 있습니다.
분산 구조: 데이터가 여러 사이트에 분산됩니다. 이 구조는 지리적으로 분산된 데이터를 처리하는 데 유용하지만, 보안 및 관리가 더 복잡해집니다.
13. 빅데이터 분석방법론의 분석기획 단계 산출물인 프로젝트 범위 정의서(SOW)에 들어가는 내용으로 옳은 것은?
1) 비즈니스 이해
2) 데이터 정의
3) 데이터 스토어 설계
4) 탐색적 분석
(1) 업무 이해(Business Understanding)
비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해하기 위한 단계입니다. 초기 프로젝트 계획을 수립하는 단계로 업무 목적을 파악하고, 데이터 마이닝의 목적과 프로젝트 계획을 수립합니다.
(2) 데이터 이해(Data Understanding)
분석을 위한 데이터를 수집하고 데이터 속성을 이해하기 위한 단계입니다. 데이터 품질에 대한 문제점을 식별하고 숨겨져 있는 인사이트를 발견하는 단계로 초기 데이터를 수집하고 데이터 기술 분석, 데이터 탐색이 이 단계에 포함됩니다.
(3) 모델링(Modeling)
다양한 모델링 기법과 알고리즘을 선택하고 모델링 과정에서 사용되는 파라미터를 최적화하는 단계입니다. 모델링 과정에서 데이터셋이 추가로 필요한 경우 데이터 준비 단계를 반복 수행할 수 있습니다. 모델링 결과를 테스트용 데이터셋으로 평가하여 모델의 과적합(Over-fitting)문제를 확인, 모델링 기법 선택, 모델 테스트 계획 설계, 모델가 이 단계에 포함됩니다.
(4) 평가(Evaluation)
모델링 결과가 프로젝트 목적에 부합하는지 평가하는 단계로 데이터마이닝 결과를 최종적으로 수용할 것인지 판단하는 단계입니다. 분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가가 이 단계에 포함됩니다.
(5) 전개(Deployment)
모델링과 평가 단계를 통하여 완성된 모델을 실무에 적용하기 위한 계획을 수립하는 단계입니다. 모니터링과 모델의 유지보수 계획 마련. 입력되는 데이터의 품질 편차, 전개 계획 수립, 모니터링/유지보수 계획 수립, 프로젝트 종료 보고, 프로젝트 리뷰가 이 단계에 포함됩니다.

14. CRISP-DM의 모델링 단계에서 수행하는 업무(태스크)로 옳지 않은 것은?
1) 모델링 기법 선택
2) 데이터 통합
3) 모델 테스트 계획 설계
4) 모델 평가

CRISP-DM(Cross Industry Standard Process for data Mining)은 1996년 유렵연합의 ESPRIT에서 있었던 프로젝트에서 시작되었으며, 주요한 5개의 업체들이 주도하였다.
업무이해 -> 데이터이해 -> 데이터준비 -> 모델링 -> 평가 -> 전개
1단계 : 업무이해
- 비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해하기 위한 단계
- 도메인 지식을 데이터 분석을 위한 문제정의로 변경하고 초기 프로젝트 계획을 수립하는 단계
- 수행업무 : 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 숣
2단계 : 데이터 이해
- 분석을 위한 데이터를 수집하고 데이터 속성을 이해하기 위한 단계
- 데이터 품질에 대한 문제점을 식별하고 숨겨져 있는 인사이트를 발견하는 단계
- 수행업무 : 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
3단계 : 데이터 준비
- 분석을 위하여 수집된 데이터에서 분석기법에 적합한 데이터를 편성하는 단계(많은 시간이 소용될 수 있음)
- 수행업무 : 분석용 데이터 셋 선택, 데이터 정제, 분석용 데이터 셋 편성, 데이터 통합, 데이터 포맷팅
4단계 : 모델링
- 다양한 모델링 기법과 알고리즘을 선택하고 모델링 과정에서 사용되는 파라미터를 최적화해 나가는 단계
- 모델링 과정에서 데이터 셋이 추가로 필요한 경우 데이터 준비 단계를 반복 수행할 수 있으며, 모델링 결과를 테스트용 데이터 셋으로 평가하여 모델의 과적합 문제를 확인
- 수행업무 : 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성, 모델 평가
5단계 : 평가
- 모델링 결과가 프로젝트 목적에 부합하는지 평가하는 단계로 데이터마이닝 결과를 최종적으로 사용할 것인지 판단
- 분석결과 평가, 모델링과정 평가, 모델적용성 평가
6단계 : 전개
- 모델링과 평가 단계를 통하여 완성된 모델을 실 업무에 적용하기 위한 계획을 수립하는 단계
- 모니터링과 모델의 유지보수 계획 마련
- CRISP-DM의 마지막 단계, 프로젝트 종료 관련 프로세스를 수행하여 프로젝트 마무리
15. 빅데이터 분석 절차는 빅데이터 분석 방법론을 토대로 5단계 절차로 수행된다. 절차로 옳은 것은?
1) 분석기획 → 데이터준비 → 시스템구현 → 데이터분석 → 평가 및 전개
2) 분석기획 → 데이터분석 → 시스템구현 → 데이터준비 → 평가 및 전개
3) 데이터준비 → 분석기획 → 데이터분석 → 시스템구현 → 평가 및 전개
4) 분석기획 → 데이터준비 → 데이터분석 → 시스템구현 → 평가 및 전개
(1) 분석 기획(Planning)
문제점을 인식하고 분석 계획 및 프로젝트 수행계획을 수립하는 단계입니다.
(2) 데이터 준비(Preparing)
요구사항과 데이터 분석에 필요한 원천 데이터를 정의하고 준비하는 단계입니다.
(3) 데이터 분석(Analyzing)
원천 데이터를 분석용 데이터셋으로 편성하고 다양한 분석 기법과 알고리즘을 이용하여 데이터를 분석하는 단계입니다.
분석 단계를 수행하는 과정에서 추가적인 데이터 확보가 필요한 경우 데이터 준비 단계를 반복 진행합니다.
(4) 시스템 구현(Developing)
분석 기획에 맞는 모델을 도출하고 이를 운영중인 가동 시스템에 적용하거나 시스템 개발을 위한 프로토타입 시스템을 구현합니다.
(5) 평가 및 전개(Deploying)
데이터 분석 및 시스템 구현 단계를 수행한 후 프로젝트의 성과를 평가하고 정리하거나 모델을 발전 계획을 수립하여 차기 분석 기획으로 전달하고 프로젝트를 종료하는 단계입니다.
16. 분석과제 발굴 방법 중 상향식 접근법(Bottom Up Approach)에 대한 설명으로 옳지 않은 것은?
1) 분석대상이 명확할 때 솔루션을 찾는 방식이다.
2) 일반적으로 비지도 학습(Unsupervised Learning)방식을 수행한다.
3) 다양한 원천 데이터를 대상으로 분석을 수행하여 가치있는 문제를 도출하는 일련의 과정이다.
4) 하향식 접근 방식과는 달리 복잡하고 다양한 환경에서 발생하는 문제 해결에도 적합하다.
17. 과제 중심적인 접근방식으로 진행되는 특징으로 알맞지 않는 것은?
1) Speed & Test
2) Quick-Win
3) Accuaray & Deploy
4) Problem & Solving
3) 마스터플랜
18. 하향식 접근방식의 수행 내용으로 옳지 않은 것은?
1) 문제탐색
2) 프로토타이핑
3) 문제정의
4) 타당성검토
19. 빅데이터 분석 방법론의 분석기획 단계에서 수행하는 주요 task로 옳은 것은?
1) 비즈니스의 이해 및 범위 설정
2) 필요 데이터 정의
3) 모델 적용 및 운용 방안 수립
4) 모델 발전 계획 수립
20. 데이터 분석기획 유형에 관한 설명으로 옳지 않은 것은?
1) 분석대상을 알고, 분석방식도 아는 경우 개선을 통한 최적화 유형을 적용한다.
2) 최적화, 솔루션, 관찰, 발견의 4가지 분석 주제 유형으로 이루어져 있다.
3) 분석대상을 알고 분석방식을 모르는 경우 솔루션을 찾아내는 방식을 적용한다.
4) 발견은 분석대상을 모르고, 분석방식도 모르는 경우 적용한다.
21. 다음이 설명하는 표본추출방법으로 알맞은 것은?
[모집단을 상이한 집단으로 나누고 각 집단에서 무작위로 표본을 추출하는 방법]
1) 단순무작위 추출법
2) 계통추출법
3) 군집추출법
4) 층화추출법
22. 주성분 수의 선택방법에 대한 설명으로 가장 옳지 않은 것은?
1) 주성분들이 설명하는 총 분산의 비율이 70~90% 사이가 되는 주성분의 개수를 선택할 수도 있다.
2) 고유값이 1에 가까운 값을 선택한다.
3) 스크린 플랏(Scree Plot)을 통해서 주성분의 분산의 감소가 급격하게 줄어들어 주성분의 개수를 늘릴 때 얻게 되는 정보의 양이 상대적으로 미미한 지점에서 주성분의 개수를 정할 수 있다.
4) 전체변이 공현도 방법은 고유값 평균 및 스크리 플랏(Scree Plot) 방법보다 항상 우수하다.
23. 의사결정나무 분리기준인 엔트로피 지수의 계산식은? 1)

카이제급
엔트로피
지니지수
24. 확률에 대한 설명으로 가장 적합하지 않은 것은?
1) 각 사건의 확률은 0~1이다.(확률은 0이상의 값을 가진다.)
2) 표본공간(S)에서 발생 가능한 모든 사건의 확률의 합은 1이다.
3) A와 B가 독립사간인 경우, 각 독립사건의 확률의 합은 합집합의 확률과 동일하다.
4) 전체 표본 중 독립적인 것을 근원사건이라 한다.
25. 아래 데이터는 닭의 성장률에 대한 다양한 사료 보충제의 효과를 측정하고 비교하기 위한 자료유형별 닭의 무게 데이터이다. summary 함수 결과에 대한 해석 중 옳지 않은 것은?
> data("chickwts")
> summary(chickwts)
weight feed
Min. :108.0 casein : 12
1st Qu. : 204.5 horsebean : 10
Median : 258.0 linseed : 12
Mean : 261.3 meatmeal : 11
3rd Qu. : 323.5 soybean : 14
Max. : 423.0 sunflower : 12
1) feed는 범주형 데이터이다.
2) feed의 사료 중 soybean수가 가장 많다.
3) range(chickwts$weight)의 결과는 108 423이다.
4) weight의 평균값은 258.0이다.
평균값(Mean) : 261.3,중앙값(Median):258.0,최빈값(Mode)
26. 계층적 군집 방법으로 가장 알맞지 않은 것은?
1) 단일연결법
2) 완전연결법
3) 평균연결법
4) 편차연결법
27. 분해시계열의 요인으로 알맞지 않은 것은?
1) 추세요인
2) 계절요인
3) 환경요인
4) 순환요인
추세,계절,순환,불규칙
28. 다음 수식으로 구할 수 있는 데이터간 수는?

1) 유클리드 거리
2) 표준화 거리
3) 마할라노비스 거리
4) 민코프스키 거리(민코우스키 거리)
p=1 : 맨하탄
p=2 : 유클리드
29. 의사결정나무와 가장 관련없는 용어는?
1) 카이제곱 통계량(Chi-square Statistic)
2) 지니 지수(Gini Index)
3) 엔트로피 지수(Entropy Index)
4) 퍼셉트론(Perceptron)
4) 퍼셉트론 -> 인공신경망
30. 두 개의 확률변수 X,Y의 공분산에 대한 설명 중 옳지 않은 것은?
1) 공분산이 양수이면 X가 증가할 때 Y도 증가한다.
2) 공분산이 음수이면 X가 증가할 때 Y는 감소한다.
3) 공분산의 크기는 상관계수와 동일하게 - 1~1 사이의 범위를 갖는다.
4) 공분산이 0이면 두 변수 간에는 아무런 선형관계가 없으며 두 변수는 서로 독립적인 관계이다.
31. 아래의 F-Beta Score(지표)에 대한 설명으로 옳은 것은?

1) Bata 값이 1.0보다 크면 Precision에 비중을 두고 계산한다.
2) Beta 값이 1.0보다 작으면 Recall에 비중을 두고 계산한다.
3) Beta 값이 0.5일 경우 Precision에 2배 가중치하여 평균한다.
4) Recall 값과 Precision 값이 정확히 같다면 Beta에 관계없이 다른 결과가 나온다.
Precision(정밀도), Recall(재현율)
32. 앙상블 기법에 대한 설명으로 알맞은 것은?
1) 앙상블 기법을 사용하게 되면 각 모형의 상호 연관성이 높을수록 정확도가 향상된다.
2) 대표적인 앙상블 기법은 배경, 부스팅이 있다.
3) 전체적인 예측값의 분산을 유지하여 정확도를 높일 수 있다.
4) 랜덤 포레스트는 앙상블 기법 중 유일한 비지도학습기법이다.
33. 통계적 가설검정에 대한 설명으로 옳지 않은 것은?
1) 귀무가설이 사실일 때 이 귀무가설을 기각함으로써 발생하는 오류는 유의수준이라 한다.
2) 귀무가설이 거짓일 경우, 이를 옳지 않다고 판단하는 확률을 검정력이라 한다.
3) 사실은 귀무가설을 기각했을 때 발생하는 오류를 제 2 종 오류라 한다.
4) p-value(유이확률)이 클수록 귀무가설을 채택하는 것으로 해석한다.
34. K-means 군집분석에 대한 설명으로 옳은 것은?
1) 군집에서 가장 중심에 위차한 객체를 사용하여 k개의 군집을 찾게 된다.
2) K-Medoids 알고리즘에 비해 노이즈 처리에 우수하고 연산량이 많다.
3) 초승달 모양(Crescent Shaped) 데이터셋에 적합하다.
4) 군집 절차 수행 시 군집 수 K는 초기에 설정되어야 한다.
35. 오분류표에서 재현율(Recall)로 가장 알맞은 것은?
| 예측치 | 합계 | |||
| True | False | |||
| 실제값 | True | 30(TP) | 70(FN) | 100 |
| False | 60(FP) | 40(TN) | 100 | |
| 합계 | 90 | 110 | 200 | |
1) 3/10
2) 2/5
3) 1/3
4) 7/11
정확도(Precision)=TP / TP + FP=30/30+60=1/3
재현율(Recall)=TP / TP + FN=30/30+70=3/10
F1 Score = 2 *(정확도*재현율)/(정확도+재현율)출처: https://feature-life.tistory.com/1339 [FEATURE-LIFE:티스토리]
F1 Score = 2 * (TP / (TP + FP)) * (TP / (TP + FN)) / ((TP / (TP + FP)) + (TP / (TP + FN)))
2*(1/3*3/10 / 1/3+3/10)=6/19

36. 확률질량함수의 확률변수X의 기대값은?
| x | 1 | 2 | 3 |
| f(x) | 1/6 | 3/6 | 2/6 |
1) 10/6
2) 11/6
3) 12/6
4) 13/6
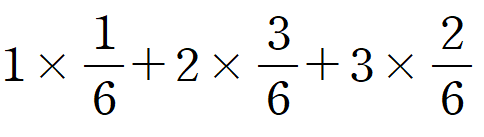
37. 군집분석 시 데이터의 단위가 다를 경우 사용하는 기법으로 알맞은 것은?
1) Elimination
2) Sampling
3) Averaging
4) Scaling
38. 통계 용어에 대한 설명으로 옳지 않은 것은?
1) 다른 변수의 영향을 받는 변수를 설명변수라고 한다.
2) 모집단의 평균을 추정하기 위해 표본 평균을 계산한다.
3) 표준 편차는 데이터가 평균으로부터 떨어진 정도를 나타내는 척도이다.
4) 사분위수범위는 데이터의 25%, 50%, 75% 위치 중 75%에서 25%의 값을 빼준 값이다.
39. 시계열 모형에 대한 설명으로 옳은 것은?
1) ARIMA의 약어는 AutoRegressive Improved Moving Average이다.
2) ARIMA모형에서 p=0 일 때, IMA(d,q)모형이라고 부르고, d번 차분하면 MA(q)모형을 따른다.
3) 분해시계열은 일반적인 요인을 분리하여 분석하는 방법으로 회귀분석적인 방법과는 다르게 사용한다.
4) ARIMA모형에서는 정상성을 확인할 필요가 없다.
AR
MA
ARMA
ARIMA
p(AR)
d(하분)
q(MA)
40. 데이터의 정규성을 확인하기 위한 방법으로 알맞지 않은 것은?
1) Q-Q plot
2) 결정계수
3) 히스토그램
4) 첨도와 왜도
41. 선형회귀모형이 통계적으로 유의미한지 평가하는 통계량으로 옳은 것은?
1) F-Statistics
2) Chi-Statistics
3) T-Statistics
4) R-Square
42. 데이터의 양이 가장 많이 발생하는 유형의 척도로 알맞은 것은?
1) 명목척도
2) 순서척도
3) 등간척도
4) 비율척도
43. 상관계수에 대한 설명으로 옳지 않은 것은?
1) 피어슨 상관계수는 두 변수간의 선형적인 관계의 강도를 측정한다.
2) 피어슨 상관계수는 두 변수의 원래 값을 사용하여 계산된다.
3) 스피어만 상관계수는 모수적 관계에서 두 변수 간의 단조적인 관계의 강도를 측정한다.
4) 피어슨 상관계수가 0이면 선형관계가 없다.
44. 시계열 데이터의 정상성(Stationary)에 대한 설명으로 옳지 않은 것은?
1) 평균이 일정하다.
2) 시계열 자료는 독립셩을 충족해야 한다.
3) 분산이 시점에 의존하지 않는다.
4) 공분산은 단지 시차에만 의존하고 시점 자체에는 의존하지 않는다.
45. 회귀분석에서 모형의 설명력을 확인하기 위해 사용되는 결정계수의 특성으로 옳지 않은 것은?
1) 결정계수는 0에서 1의 값을 가진다.
2) 높은 값을 가질수록 측정된 회귀식의 설명력이 높다.
3) 총 변동에서 추정된 회귀식에 의해 설명되는 변동의 비율로 나타낼 수 있다.
4) 종속변수와 독립변수 사이의 표본 상관계수 값과 같다.
46. 선형회귀모형의 오차항에 대한 가정조건으로 옳은 것은?
1) 독립성, 선형성, 등분산성
2) 독립성, 등분산성, 정규성
3) 정규성, 효율성, 등분산성
4) 정규성, 편의성, 독립성
정규성, 독립성, 등분산성, 선형성
47. 아래 설명에 해당하는 용어로 알맞은 것은?
[다중 신경망 모형에서 은닉 층의 개수를 너무 많아 설정하면 역전파 과정에서 앞쪽 은닉층의 가중치가 조정되지 않아, 신경망에 대한 학습이 제대로 되지 않는 현상]
1) 기울기소실 문제
2) 과적합
3) 활성화 함수
4) 신경망 레이어 소실
48. 아래 보기의 회귀모델에 대한 설명 중 옳지 않은 것은?
> library(MASS)
> data(ChickWeight)
> Chick = ChickWeight[ChickWeight$Diet==1 & ChickWeight$Chick==1.]
> model = Im(weight ~ Time, Chick)
> summary(model)
Call:
Im(formula = weight ~ Time, data= Chick)
Residuals;
Min 1Q Median 3Q Max
-14.3202 -11.3081 -0.3444 11.1162 17.5346
Coefficients;
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24.4654 6.7279 3.636 0.00456 **
Time 7.9879 0.5236 15.255 2.97e-08 ***
---
Signif. codes: 0 '***' 0.001 '*' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error : 12.29 on 10 degrees of freedom
Multiple R-squared : 0.9588, Adjusted R-squared : 0.9547
F-stastic : 232.7 on 1 and 10 DF , p-value : 2.974e-08
1) 추정된 회귀식은 weight=24.4654+7.9879*time와 같다.
2) F통계량 : 232.7, p-값 : 2.974e-08으로 보아 유의수준 5%하에서 추정된 회귀 모형이 통계적으로 매우 유의하다.
3) time이 1 증가할 때, weight이 5.99만큼 증가한다.
4) 결정계수 또한 0.9588로 매우 높은 값을 보이므로 이 회귀식이 데이터를 약 996 정도로 설명하고 있다.
닭 가금류 체중과 사육 시간의 선형 회귀 분석 결과
데이터 분석 결과 요약:
데이터 출처: MASS 패키지의 ChickWeight 데이터 세트
분석 대상: 사료 종류가 1이고, 닭 가금류 번호가 1인 데이터
모형: 선형 회귀 분석 (Im 함수 사용)
종속 변수: 체중 (weight)
독립 변수: 사육 시간 (Time)
회귀 계수:
절편 (Intercept): 24.4654
사육 시간 변수 계수 (Time): 7.9879
모형 유의성 검정:
F-통계량: 232.7 (p-value: 2.974e-08)
F-통계량이 매우 높고 (p-value가 매우 작음) 따라 사육 시간이 체중에 유의미한 영향을 미치는다는 결론을 내릴 수 있습니다.
모형 적합도 평가:
결정계수 (R-squared): 0.9588
결정계수가 0.9588에 가까워 모델이 체중 변화를 설명하는 데 매우 효과적이라는 것을 의미합니다.
수정된 결정계수 (Adjusted R-squared): 0.9547
수정된 결정계수도 0.95에 가까워 모델의 적합도가 높다는 것을 보여줍니다.
잔차 분석:
잔차 분석 결과는 출력 내용에 포함되어 있지 않지만, 잔차 표준 오차는 12.29입니다.
잔차 분석은 모델의 오차 분포를 검토하는 데 사용됩니다.
해석:
이 분석 결과는 사료 종류가 1이고, 닭 가금류 번호가 1인 경우 사육 시간이 길어질수록 체중이 증가한다는 것을 나타냅니다.
사육 시간 변수의 회귀 계수 (7.9879)은 사육 시간이 1일 증가할 때 체중이 평균 7.9879g 증가한다는 것을 의미합니다.
절편 (24.4654)은 사육 시간이 0일일 때 예측되는 평균 체중입니다.
결정계수 (R-squared)와 수정된 결정계수 (Adjusted R-squared) 값이 높기 때문에 이 선형 회귀 모델은 사료 종류가 1이고, 닭 가금류 번호가 1인 경우의 체중 변화를 예측하는 데 매우 유용합니다.
49. 카이제곱 통계량의 예측 표본과 실제 표본의 차이와 검정 통계량에 따른 유의확률의 변화로 옳은 것은?
1) 카이제곱 통계량을 이용한 적합도 검정은 여러 범주형 변수에 대해 관측 값들이 어떤 이론이나 이론적분포를 따르고 있는지를 검정하는 방법이다.
2) 데이터의 정규성을 검정하기 위해 오차량이 정규분포를 추종하는지 알아보는 검정방법이다.
3) 예측 표번과 실제 표본의 차이가 많을 때, 도수가 낮아지고 검정 통계량이 높아져 유의확률이 낮아진다.
4) 각 데이터 포인트와 이론적인 분포 간의 차이를 측정하여 일차이를 기반으로 검정 통계량을 계산한다.
## 카이제곱 검정에서 예측 표본과 실제 표본의 차이 분석: 심층 가이드
카이제곱 검정은 두 변수 간의 독립성을 검증하는 데 사용되는 통계 검정 방법입니다. 이 검정은 예측 표본과 실제 표본의 차이를 분석하여 두 변수가 서로 관련이 있는지 여부를 판단합니다.
**1. 예측 표본과 실제 표본 정의:**
* **예측 표본:** 귀하가 가진 가설이나 이론에 따라 예상되는 데이터 분포를 나타냅니다. 이는 가설 검증 과정에서 기준값으로 사용됩니다.
* **실제 표본:** 실제로 관측하거나 수집한 데이터 분포를 나타냅니다. 이는 예측 표본과 비교하여 분석됩니다.
**2. 카이제곱 통계량 계산:**
카이제곱 통계량은 다음 공식으로 계산됩니다.
```
χ² = Σ ( (O - E)² / E )
```
* `χ²`: 카이제곱 통계량
* `O`: 관측된 빈도 (실제 표본)
* `E`: 기대 빈도 (예측 표본)
**3. 해석:**
* 카이제곱 통계량이 커질수록 (p-value가 작아질수록) 예측 표본과 실제 표본의 차이가 더 크다는 것을 의미합니다.
* 일반적으로 p-value가 0.05 미만이면 귀하의 가설 (두 변수가 독립적이라는 가설)을 기각하고 두 변수가 서로 관련이 있다고 결론 내립니다.
**4. 예측 표본과 실제 표본의 차이 분석:**
카이제곱 검정 결과, 예측 표본과 실제 표본 간에 유의미한 차이가 있다고 판단되면 다음과 같은 단계를 통해 차이를 분석해야 합니다.
**1) 기여도 분석:**
* 각 셀에서 관측된 빈도와 기대 빈도의 차이를 계산하고, 그 제곱을 기대 빈도로 나눕니다.
* 이 값을 기여도라고 하며, 기여도가 높은 셀ほど 예측 표본과 실제 표본의 차이에 크게 영향을 미친다는 것을 의미합니다.
* 기여도 분석을 통해 어떤 범주 또는 조합에서 예측과 실제가 가장 크게 다르는지 파악할 수 있습니다.
**2) 잔차 분석:**
* 각 셀에서 관측된 빈도와 기대 빈도의 차이를 계산하고, 이를 표준 오차로 나눕니다.
* 잔차가 절대값 2보다 크거나 같으면 일반적으로 유의미한 것으로 간주됩니다.
* 잔차 분석을 통해 특정 셀에서 예측과 실제가 크게 다른 이유를 탐색할 수 있습니다.
**3) 교차 분석:**
* 두 변수의 각 범주 또는 조합에서 관측된 빈도와 기대 빈도를 비교하여 분석합니다.
* 교차 분석을 통해 두 변수 간의 상호 작용을 이해하고, 예측 표본과 실제 표본의 차이에 영향을 미치는 요인을 파악할 수 있습니다.
50. 인공신경망 함수에 대한 설명으로 옳지 않은 것은?
1) 인공신경망 함수는 여러 개의 뉴런이 연결된 구조를 가지고 있으며,
각 뉴런은 입력값에 따라 비선형적인 변환을 수행한다.
2) 쌍곡탄젠트함수는 0~1 사이의 값을 출력하며 시그모이드 함수와 관련이 있다.
3) 인공신경망 함수는 활성화 함수를 사용하여 입력값을 출력값으로 변환한다.
4) 대표적인 인공신경망 함수로는 시그모이드 함수, 쌍곡탄젠트 함수, 렐루 함수 등이 있다.
<!--td {border: 1px solid #cccccc;}br {mso-data-placement:same-cell;}-->
| 특징 | 쌍곡탄젠트 함수 | 시그모이드 함수 |
| 출력 범위 | -1 ~ 1 | 0 ~ 1 |
| 중심값 | 0 | 0.5 |
| 미분 가능성 | 미분 가능 | 미분 가능 |
| 계산 복잡도 | 비교적 높음 | 비교적 낮음 |
| 사망 뉴런 문제 | 발생 가능성이 낮음 |
발생 가능성이 높음
|
인공 신경망(ANN)은 인간 뇌의 신경망 구조를 모방하여 만들어진 머신 러닝 모델입니다. 인공 신경망은 다양한 함수를 사용하여 데이터를 변환하고 학습하며, 이를 통해 복잡한 패턴을 인식하고 예측을 수행합니다.
* **선형 함수 (Linear Function):** 입력값에 비례하는 출력값을 생성합니다. 가장 단순한 함수이며, 데이터의 선형 관계를 모델링하는 데 사용됩니다.
* 수식: `y = wx + b`
* 특징:
* 해석하기 쉬움
* 계산하기 쉬움
* 비선형 데이터 모델링에는 적합하지 않음
* **계단 함수 (Step Function):** 입력값이 특정 임계값을 초과하면 1을 출력하고, 그렇지 않으면 0을 출력합니다. 이진 분류 문제에 유용하게 사용됩니다.
* 수식: `y = 1(x >= θ)`
* 특징:
* 단순한 이진 분류 문제에 적합
* 비선형 데이터 모델링에 유용
* 미분 불가능하여 학습 과정이 어려울 수 있음
* **시그모이드 함수 (Sigmoid Function):** 입력값을 0과 1 사이의 값으로 변환합니다. 로지스틱 회귀와 같은 확률적 모델링에 사용됩니다.
* 수식: `y = 1 / (1 + exp(-ax))`
* 특징:
* 비선형 데이터 모델링에 유용
* 출력값이 0과 1 사이로 변환되어 확률적 해석이 가능
* 미분 가능하여 학습 과정이 용이
* **ReLU 함수 (Rectified Linear Unit):** 입력값이 0보다 크면 그대로 출력하고, 0보다 작으면 0을 출력합니다. 최근 딥러닝 모델에서 많이 사용되는 함수입니다.
* 수식: `y = max(0, x)`
* 특징:
* 계산하기 쉬움
* 학습 속도가 빠름
* 일부 뉴런이 죽는 문제 (Dead ReLU) 발생 가능성이 있음
* **tanh 함수 (Hyperbolic Tangent Function):** 입력값을 -1과 1 사이의 값으로 변환합니다. 시그모이드 함수와 유사하지만 출력 범위가 더 넓습니다.
* 수식: `y = tanh(ax)`
* 특징:
* 시그모이드 함수보다 출력 범위가 넓음
* 일부 뉴런이 죽는 문제 발생 가능성이 있음
* **Softmax 함수 (Softmax Function):** 여러 입력값을 0과 1 사이의 값으로 변환하고, 그 합이 1이 되도록 합니다. 다중 분류 문제에 유용하게 사용됩니다.
* 수식: `y_i = exp(z_i) / sum(exp(z_j))` (i = 1, 2, ..., K)
* 특징:
* 다중 분류 문제에 적합
* 출력값이 서로 합이 1이 되도록 변환
* 학습 과정이 어려울 수 있음
1,2과목
https://youtu.be/RWHi3lGgiHA?si=tblC-qxCb_-o9ZLJ
3과목 1
https://youtu.be/xJ04s8KxGGI?si=aln7JPKajAjSjO2O
3과목2
https://youtu.be/LON7HXPPz5I?si=2epMTtfeSa6pAOid
'국가자격증(큐넷) > ADsP 데이터분석준전문가' 카테고리의 다른 글
| ADsP데이터분석준전문가 2024 나름내용정리 (0) | 2024.04.21 |
|---|---|
| ADsP 2시간 정복 (1) | 2024.04.20 |
| 데이터분석준전문가(ADsP) 38회 기출문제풀이 (0) | 2024.04.15 |
| adsp 기출문제 (0) | 2024.04.11 |
| ADsP 데이터분석준전문가, 고사장위치(2023년 1월기준) (0) | 2024.03.26 |