728x90
728x90
SMALL







5.

6.

8.
9.
10.
11.
12.

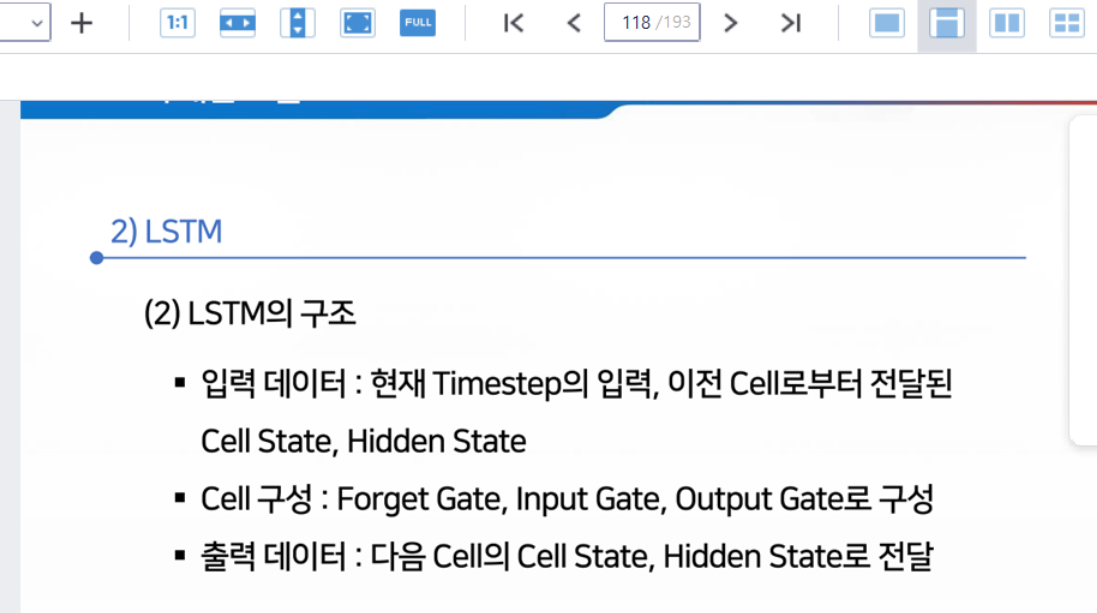
13.
14.
15.
16.

17.
19.
20.


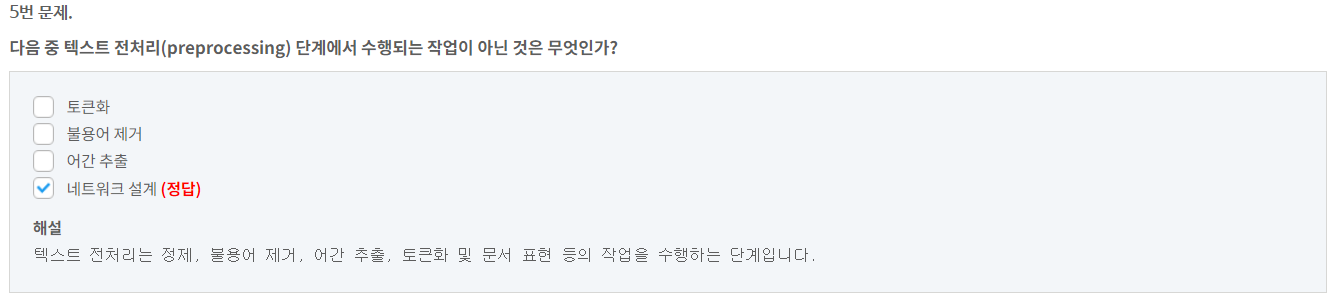
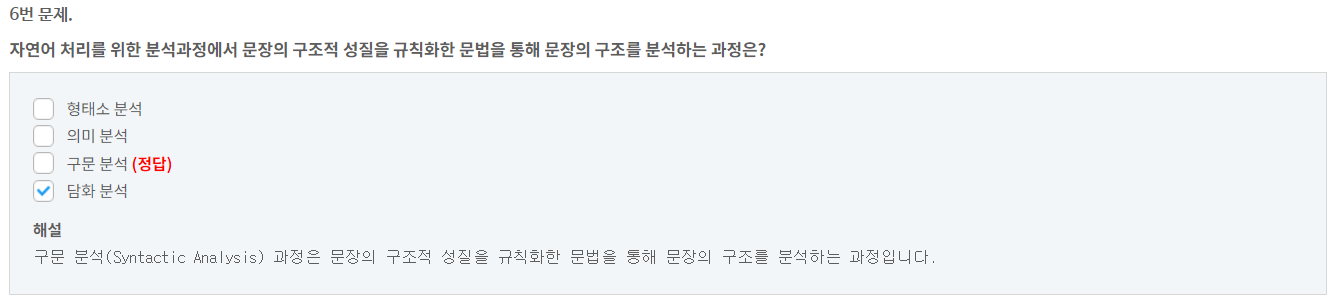
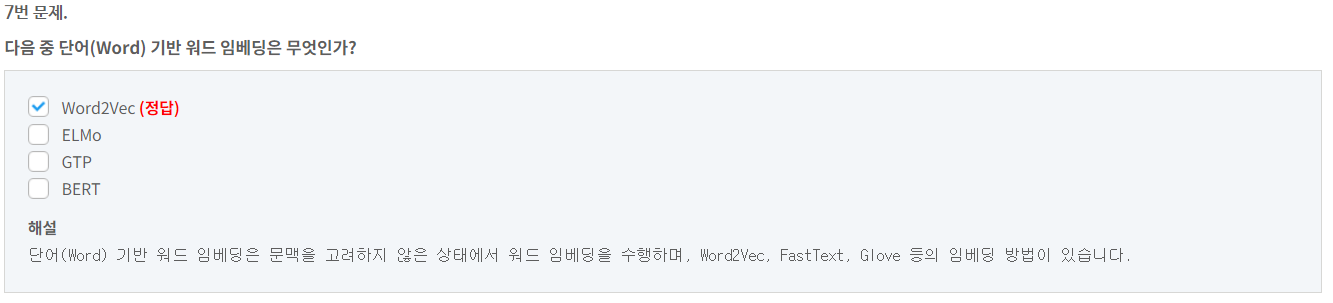
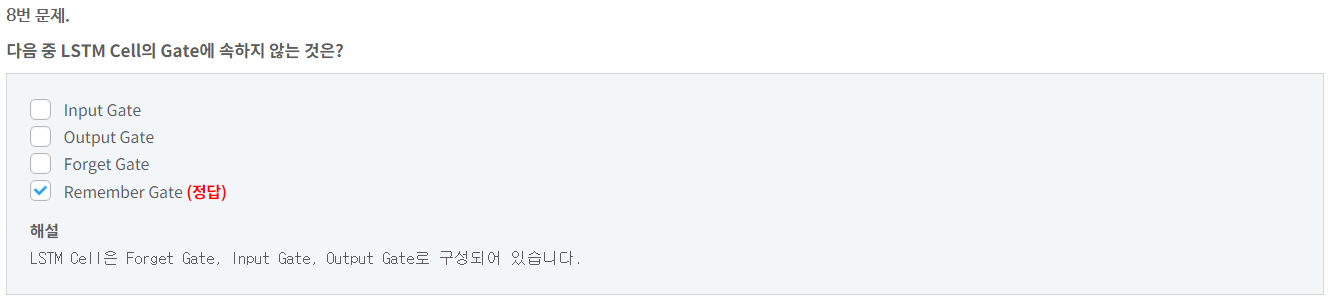
9번 문제.
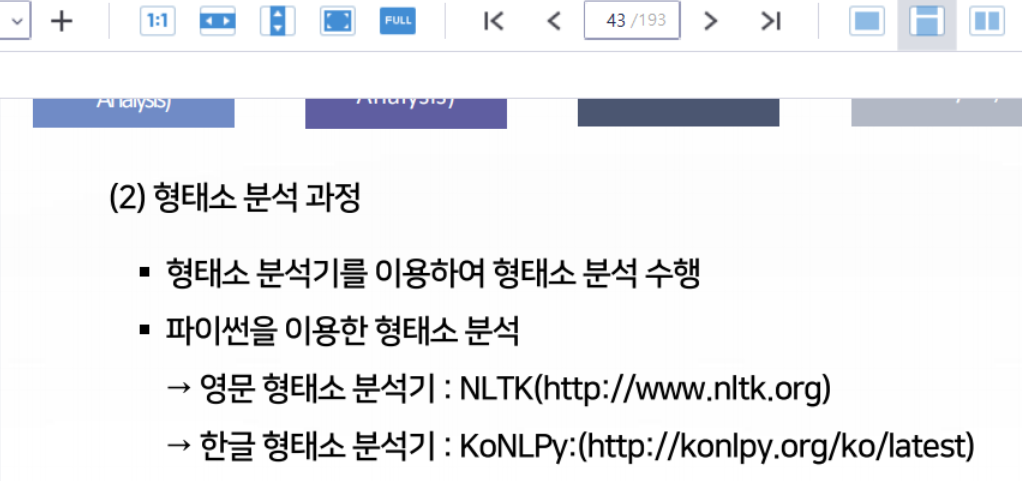
다음 중 파이썬 형태소 분석을 위한 패키지로만 묶인 것은?
pandas, numpy

numpy, nltk

nltk, konlpy (정답)

konlpy, keras
해설
파이썬에서 영문 형태소 분석은 nltk, 한글 형태소 분석은 konlpy 패키지를 이용합니다.
10번 문제.
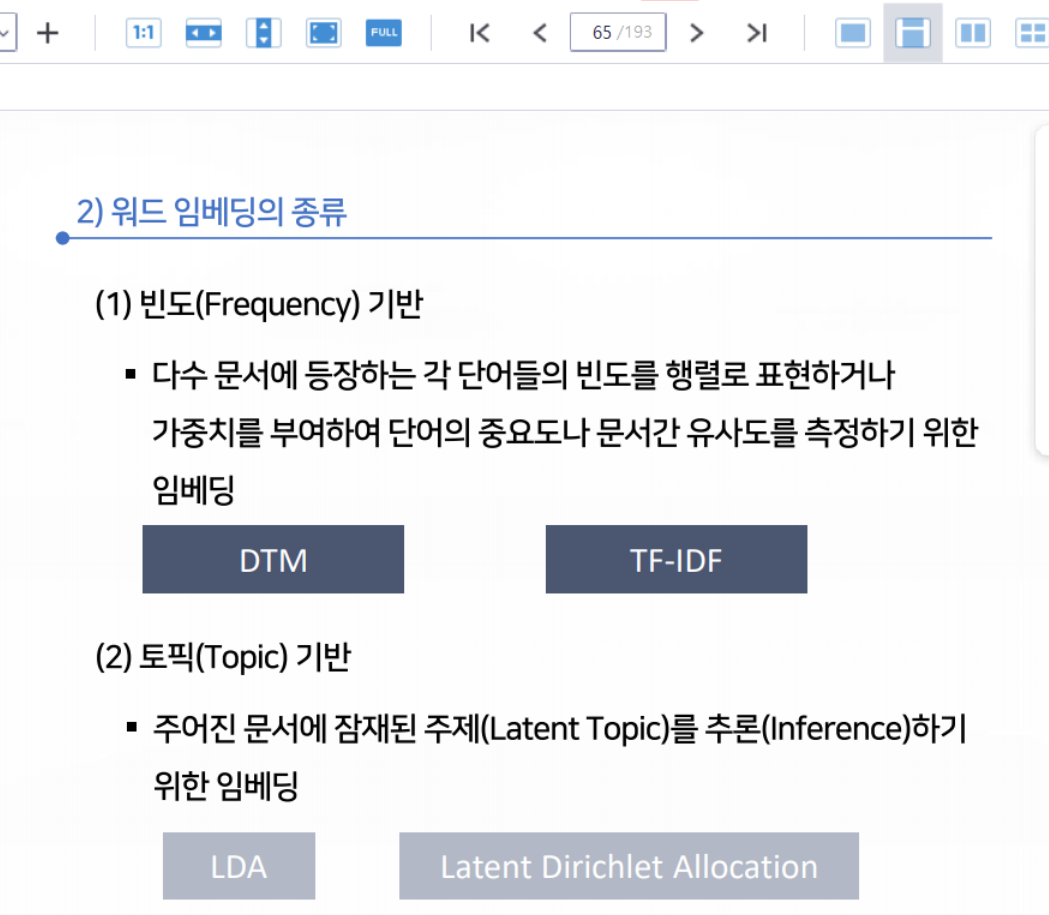
다음 중 빈도(Frequency) 기반 워드 임베딩은 무엇인가?
DTM (정답)

Word2Vec

FastText

LDA
해설
빈도(Frequency)기반 워드 임베딩으로는 DTM, TF-IDF 등이 있습니다.11번 문제.
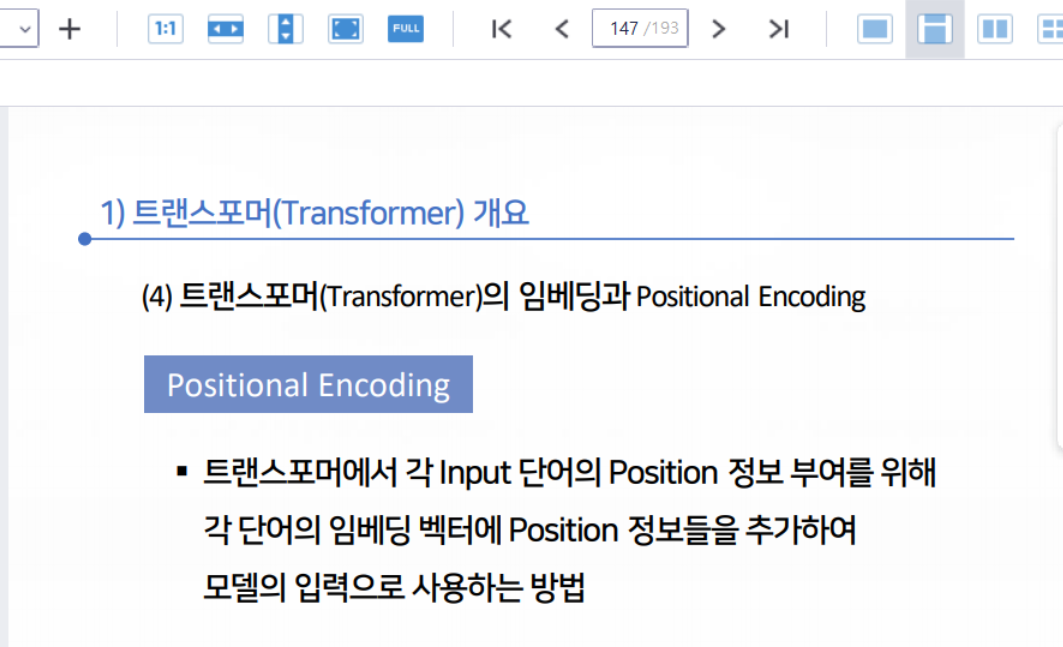
Positional Encoding이란 Transformer에서 각 Input 단어의 position정보 부여를 위해 각 단어의 임베딩 벡터에 Position 정보들을 추가하여 모델의 입력으로 사용하는 방법이다.

해설
Positional Encoding이란 Transformer에서 각 Input 단어의 position정보 부여를 위해 각 단어의 임베딩 벡터에 Position 정보들을 추가하여 모델의 입력으로 사용하는 방법입니다.12번 문제.
BERT는 Positional Encoding을 사용한다.

해설
BERT는 트랜스포머와 달리 Positional Encoding을 사용하지 않고 Position Embeddings를 사용합니다.13번 문제.
희소 표현(Sparse Representation)은 표현하고자 하는 단어의 인덱스의 값만 0으로 나머지 인덱스에는 모두 1로 표현되는 벡터 표현 방법이다.

해설
희소 표현(Sparse Representation)은 표현하고자 하는 단어의 인덱스의 값만 1로 표현하고 나머지 인덱스에는 모두 0으로 표현되는 벡터 표현 방법입니다.14번 문제.
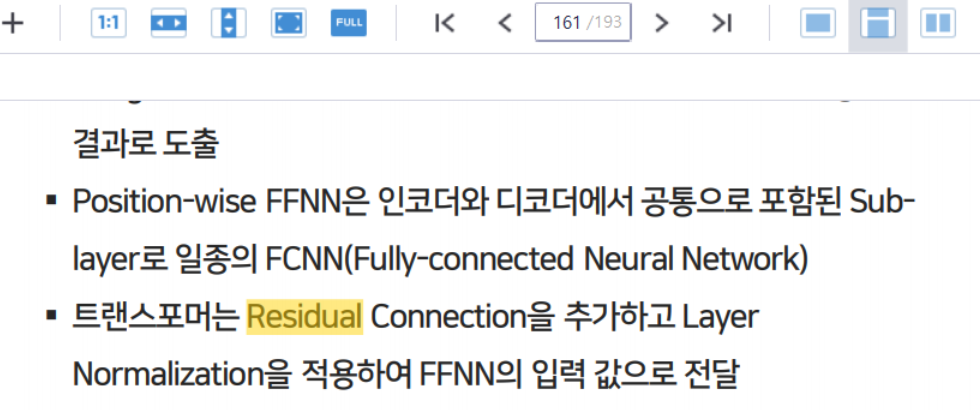
Transformer는 Residual Connection을 추가하고 Layer Normalization을 적용하여 FFNN(Feed Forward Neural Network)의 입력값으로 전달한다.

해설
Transformer는 Residual Connection을 추가하고 Layer Normalization을 적용하여 FFNN(Feed Forward Neural Network)의 입력값으로 전달합니다.15번 문제.
RNN 아키텍처 중 영화 리뷰 등에 대한 감성 분석에 적합한 아키텍처는 one to many 아키텍처다.

해설
RNN many to one 아키텍처는 시퀀스(Sequence) 입력에 대해 단일 출력으로 영화 리뷰 등에 대한 감성 분석(Sentiment Analysis)에 적합합니다.16번 문제.
전이 전략학습 전략에서 frozen partial은 pre-trained 모델 전체를 고정한 상태에서, new model의 classifier만 training 하는 전략을 말한다.

해설
frozen partial 전략은 pre-trained 모델의 일부만 고정하는 전략으로 pre-trained 모델의 일부분은 고정시킨 상태에서 pre-trained 모델 나머지 부분과 classifier만 training 하는 전략을 말합니다.17번 문제.
Position-wise FFNN(Feed Forward Neural Network)은 Encoder에만 포함된 sub-layer로 일종의 FCNN(Fully-connected Neural Network)이다.

해설
Position-wise FFNN(Feed Forward Neural Network)은 Encoder와 Decoder에서 공통으로 포함된 sub-layer로 일종의 FCNN(Fully-connected Neural Network)입니다.18번 문제.
Self-Attention에서 Query와 Key가 특정 문장에서 중요한 역할을 하고 있다면 Transformer는 이들 사이의 내적(dot product) 값을 작게 하는 방향으로 학습을 수행한다.

해설
Self-Attention에서 Query와 Key가 특정 문장에서 중요한 역할을 하고 있다면 Transformer는 이들 사이의 내적(dot product) 값을 크게 하는 방향으로 학습을 수행합니다.19번 문제.
ALBERT(A Lite BERT) BERT의 Next Sentence Prediction 대신 두 문장의 연관 관계를 예측하는 문장 순서 예측(Sentence Order Prediction)을 통해 훈련 성능을 개선하였다.

해설
ALBERT(A Lite BERT) BERT의 Next Sentence Prediction 대신 두 문장의 연관 관계를 예측하는 문장 순서 예측(Sentence Order Prediction)을 통해 훈련 성능을 개선하였습니다.20번 문제.
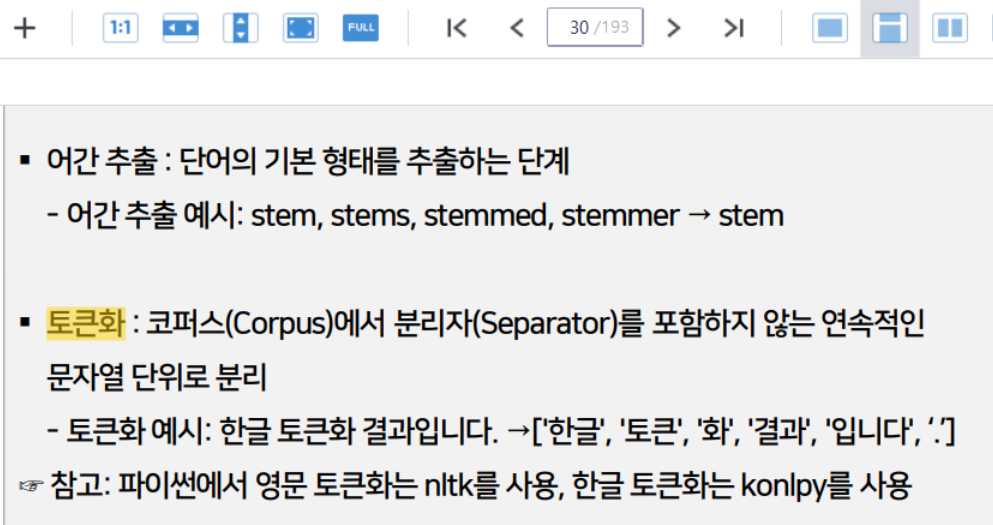
토큰화(Tokenizing)는 여러 문장(Sentence)을 하나의 코퍼스로 병합하는 과정이다.

해설
토큰화(Tokenizing)는 코퍼스를 문장(Sentence), 단어(Word) 단위 등의 작은 단위로 분리하는 과정입니다.LIST
'KOREATECH' 카테고리의 다른 글
| HRDI 202403~202404 관심교육 (0) | 2024.02.26 |
|---|---|
| 인공지능 기술 및 서비스 이해(test) (0) | 2024.02.19 |
| 디지털신기술분야 인재양성컨퍼런스 20240202 (0) | 2024.02.02 |
| 주식 파이썬 (1) | 2024.01.28 |
| koreatech 산업안전예방계획수립 20240113 (0) | 2024.01.13 |



