1과목
- 양적 자료(quantitative data, 정량적 자료)는 수치로 측정이 가능한 자료이다. 또는 수치적 자료(Numerical data)
- 빅데이터의 패러다임 변화순서
Digitalization - Connection - Agency
- 데이터 특징 : 통합, 저장, 공용, 변화
- 데이터유형
구조적데이터 (Structured data) : 스프레드시트, 금융거래, 센서측정값
수치적 데이터 (Quantitative data) : 이산데이터 (Discrete data) , 연속데이터 (Continuous data)
비구조적데이터 (Unstructured data) : 소셜미디어게시물,이메일,이미지,비디오,미처리된 데이터스트림
준구조적 데이터 (Semi-structured data) : JSON, XML, 이미지첨부이메일
- 가트너의 데이터 사이언티스트의 역량
데이터 관리, 분석모델링, 비즈니스 분석
- 빅데이터의 본질적인 변화
사전 -> 사후
표본 -> 전수
질 -> 양
인과 -> 상관
- 데이터 사이언티스트의 스킬
| 하드스킬 | 소프트스킬 |
| 데이터 분석을 위한 기술과 지식(이성적,정량적) | 데이터 사이언티스트가 비즈니스 환경에서 효과적으로 업무를 수행하기 위한 역량(감성적,정성적) |
| 통계 및 수학 지식 프로그래밍 언어(R, Python, SQL 등) 머신러닝 알고리즘 데이터 시각화 데이터베이스 클라우드 컴퓨팅 |
비즈니스 이해도 문제 정의 능력 문제 해결 능력 창의적 사고력 협업 능력 커뮤니케이션 능력 학습 능력 |
암묵지 : 경험, 지식, 노하우 등의 내재화되지 않은 지식
형식지 : 문서화되고 명확하게 표현된 지식
암묵지->형식지 : 주로 교육, 훈련, 문서화된 절차 등을 활용
형식지->암묵지 : 주로 실무 경험과 상호작용이 사용
2과목 데이터분석기획
데이터분석구조
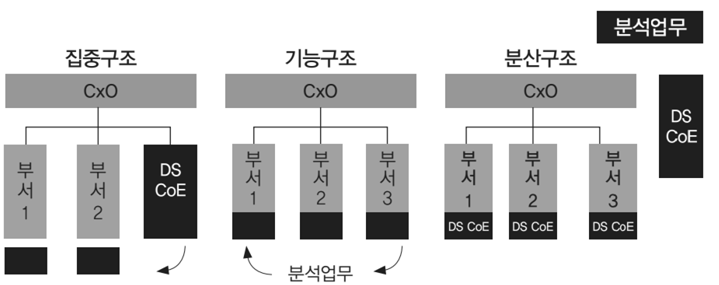
|
•전사 분석 업무를 별도의 분석 전담 조직에서 담당
•전략적 중요도에 따라 분석 조직
이 우선순위를 정해서 진행 가능•현업 업무부서의 분석업무와 이중화 / 이원화 가능성 높음
|
•일반적인 분석 수행 구조
•별도 분석조직이 없고 해당 업무
부서에서 분석수행•전사적 핵심 분석이 어려우며, 부서 현황 및 실적통계 등 과거 실적에 국한된 분석 수행 가능성 높음
|
•분석조직 인력들을 현업부서로 직접 배치하여 분석 업무 수행
•전사 차원의 우선순위 수행
•분석 결과에 따른 신속한 Action가능
•베스트 프랙티스 공유가능
•부서 분석 업무와 역할 분담 명확히 해야 함
|
빅데이터분석 방법론
| 분석기획 (Planing) |
데이터 준비 (Preparing) |
데이터 분석 (Analyzing) |
시스템 구현 (Developing) |
평가 및 전개 (Deploying) |
| 비즈니스 이해 및 범위설정 |
필요 데이터 정의 | 분석용 데이터 준비 | 설계 및 구현 | 모델 발전계획 수립 |
| 프로젝트 정의 및 계획수립 |
데이터 스토어 설계 | 텍스트 분석 | 시스템 테스트 및 운영 | 프로젝트 평가 및 보고 |
| 프로젝트 위험계획 수립 |
데어터 수집 및 정확성 점검 |
탐색적 분석 | ||
| 모델링 | ||||
| 모델 평가 및 검증 | ||||
| 모델적용 및 운용방안 수립 |
CRISP-DM의 6단계
| 업무이해 | 데이터 이해 | 데이터 준비 | 모델링 | 평가 | 전개 |
| 데이터마이닝결과를 사용할지 판단 | 모니터링과 모델의 유지보수계획마련 | ||||
| 업무목적 파악 상황파악 데이터마이닝목표설정 프로젝트계획수립 |
초기데이터수집 데이터기술분석 데이터탐색 데이터품질확인 |
분석용데이터셋분석 데이터정제 분석용데이터셋편성 데이터통합 데이터포맷팅 |
모델링기법선택 모델테스트계획설계 모델작성 모델평가 |
분석결과평가 모델링과정평가 모델적용성평가 |
프로젝트종료관련프로세스수행 |
- 빅데이터분석절차
분석기획 -> 데이터준비 -> 데이터분석 -> 시스템구현 -> 평가 및 전개
| 작업 중심 접근 방식 | 목표 지향적 접근방식 |
| Speed & Test Quick-Win Problem & Solving |
Accuaracy & Deploy(정확도&배포) |
| 특징 | 상향식 접근 | 하향식 접근 방식 |
| 의사결정 | 현지 지식과 전문성을 바탕으로 조직의 하위 수준에서 결정이 내려집니다 | 전략적 방향과 목표를 기반으로 조직의 상위 수준에서 결정이 내려집니다 |
| 계층 구조 | 분권화 및 권한 부여 강조 | 중앙 집중화 및 제어 강조 |
| 데이터(문제)를 가지고 답을 찾는다 | 답을 알고 문제(데이터)를 만든다. |
(2) 데이터의 유형
정성적 데이터 : 언어, 문자 등 / 문자텍스트, 언어, 문자
정량적 데이터 : 수치, 도형, 기호 등 / 30cm, 정육면체, 3시방향 등
정형데이터 : 정형화된 틀이 있고 연산이 가능 / CSV, 엑셀 등
비정형데이터 : 정형화된 틀이 없고 연산이 불가능 / 소셜데이터, 댓글, 영상, 음성 등
반정형데이터 : 형태는 있지만 연산이 불가능 / XML, JSON, 센서 데이터 등
p7
암묵지(Tacit Knowledge) : 학습과 체험을 통해 개인에게 습득되어 있지만, 겉으로 드러나지 않는 상태의 지식
형식지(Explicit Knowldege) : 암묵지가 문서나 매뉴얼처럼 외부로 표출돼 여러 사람이 공유할 수 있는 지식
암묵지 형식지
공통화(Socialization) 표출화(Externalization)
내면화(Internalization) 연결화(Combination)
DIKW ***
 |
지혜(Wisdom) : 지식의 축적과 아이디어가 결합된 창의적 산물 지식(Knowledge) : 데이터를 통해 도출된 다양한 정보를 구조화하여 유의미한 정보를 분류하고, 개인적인 경험을 결합해 고유의 지식으로 내재화된 것 정보(Information) : 데이터의 가공/처리와 데이터 간 연관 관계 속에서 의미가 도출된 것. 정보가 내포하는 의미는 유용하지 않을 수 있다. 데이터(Data) : 개별 데이터 자체는 의미가 중요하지 않은 객관적인 사실을 말한다. |
지혜 : A의 다른 물건도 저렴할 것이다.
지식 : 더 저렴한 A로부터 연필을 사야겠다.
정보 : A 연필이 더 저렴하다.
데이터 : A는 100원, B는 200원에 연필을 판매한다.
BIT : 0과 1로 이루어진 최소단위 이진수
BYTE : 8BIT
KB < MB < GB < TB < PB < EB < ZB < YB (Peta < Exa < Zetta < Yotta)페지요
PB=10^15 < EB=10^18(백경) < ZB=10^21(십해) < YB=10^24
P11
https://m.blog.naver.com/e2zzy/222503671639
데이터 거버넌스의 구성요소 3가지
원칙, 조직, 프로세스
데이터거버넌스 체계요소
데이터표준화, 데이터관리체계, 뎅터 저장소관리, 표준화활동
데이터분석업무 주체 3가지
집중구조 : DSCoE전담부서가 있다.
기능구조 : 일반부서에서 DSCoE일도 같이 한다.
분산구조 : DSCoE전담부서에서 전문인력을 일반부서로 파견을 보낸다.
t-검정 (t-test) 또는 스튜던트 t-테스트 (Student's t-test)는 검정통계량이 귀무가설 하에서 t-분포를 따르는 통계적 가설 검정법이다. t-테스트는 일반적으로 검정통계량이 정규 분포를 따르며 분포와 관련된 스케일링 변숫값들이 알려진 경우에 사용한다.
T-검정에서 "df"는 자유도(degree of freedom)를 나타냅니다. 자유도는 데이터셋에서 독립적으로 변동할 수 있는 값의 수를 의미합니다. 일반적으로, T-검정에서 자유도는 샘플의 크기에서 1을 뺀 값으로 계산됩니다. 예를 들어, 만약 샘플 크기가 10이라면, 자유도는 9가 됩니다.
3과목 데이터분석
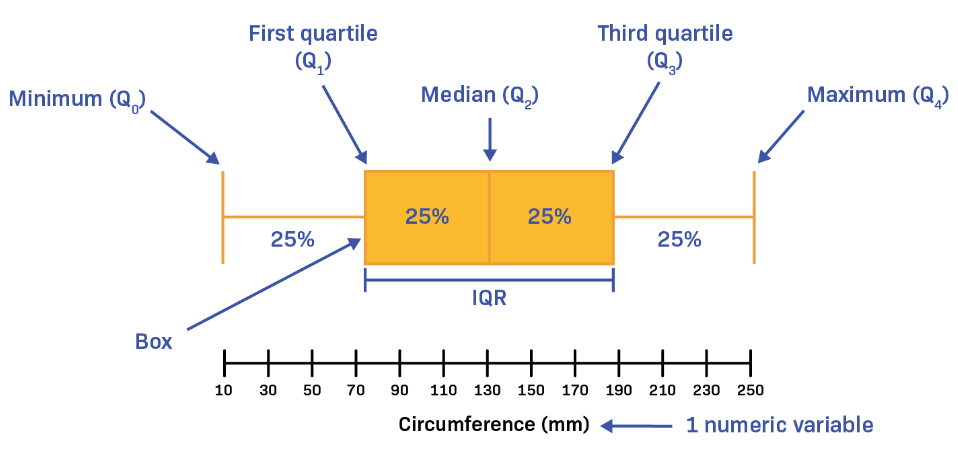
왜도 : 그래프의 좌우 치우친 분포
첨도 : 그래프의 위아래 뾰족한 모양
- 표본추출방법
1) 단순무작위추출(Simple random sampling) : 각 개체가 표본으로 선택될 확률이 동일하게 추출
2) 계통추출(Systematic sampling) : 일련번호부여하고, 첫번째 표본에서부터 일정간격으로 표본 추출
3) 층화추출(Stratified sampling) : 모집단을 성격에 따라 집단으로 나누고 -> 표본을 무작위로 추출(2단계)
4) 군집추출(Cluster sampling) : 모집단의 특성에 따라 여러 개의 집단으로 나눈다.
| 카이제곱 통계량 | 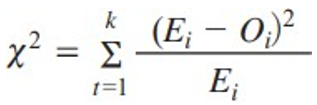 (k: 범주의 수, Oi: 실제도수, Ei: 기대도수) |
•데이터의 분포와 사용자가 선택한 기대 또는 가정된 분포 사이의 차이를 나타내 는 측정값
|
| 지니 지수 | 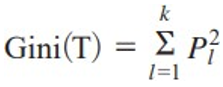  |
•지니 지수의 값이 클수록 이질적 (Diversity)이며 순수도(Purity)가 낮 다고 볼 수 있음
|
| 엔트로피 지수 |   |
•열역학에서 쓰는 개념으로 무질서 정 도에 대한 측도
•엔트로피 지수의 값이 클수록 순수도
(Purity)가 낮다고 볼 수 있음 |
앙상블모형
1) 배깅 : 크기가 같은 표본을 여러번 단순 임의 복원, 추출
2) 부스팅 : 분류가 잘못된 데이터에 가중치를 주어 표본추출
3) 랜던포레스트 : 배깅에 랜덤과정 추가
분해시계열
- 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
1) 추세요인 (Trend Factor) : 자료가 어떤 특정한 형태를 취할 때
2) 계절요인 (Seasonal Factor) : 계절에 따라 고정된 주기에 따라 자료가 변화할 경우
3) 순환요인 (Cyclical factor) : 알려지지 않은 주기를 가지고 자료가 변화할 때
4) 불규칙요인 (Irregular factor) : 위 세가지 요인으로 설명할 수 없는 회귀분석에서오차에 해당하는 요인
하한값(최소값) = Q1(1시분위수)-1.5*IQR(Q3-Q1)
상한값(최대값) = Q3(3사분위수)+1.5*IQR(Q3-Q1)
boxplot으로 이상치 검색이 가능
④ R에는 4가지 정규분포 관련된 함수가 있다.
㉠ rnorm(난수함수)
㉡ dnorm(확률밀도함수)
㉢ pnorm(누적분포함수)
㉣qnorm(분위수함수)
데이터(주)에서는 직원들에게 교양을 함양할 기회를 주기 위하여 독서반과 생활경제반 을 개설하려고 한다. 직원들의 40%는 독서반을, 50%는 생활경제반을 신청하였다. 독서반을 신청한 사람들 가운데서 30%는 생활경제반을 신청하였다.
ⓐ 한 직원을 무작위로 추출할 때 그가 두 반 모두에 신청하였을 확률을 구하라?
ⓑ 무작위로 추출된 생활경제반 신청자가 독서반에도 신청하였을 확률을 구하라?
ⓒ 무작위로 추출된 한 직원이 적어도 한 반에 신청하였을 확률을 구하라?
ⓓ 독서반에 신청한 사상(A)과 생활경제반에 신청한 사상(B)은 통계적으로 독립적인가?


확률분포의 유형
- 이산확률분포(정수값) : 이항분포, 포아송분포, 초기하분포, 기하분포, 다항분포, 초기하분포 ...
- 연속확률분포(소수값포함) : 정규분포, 표준정규분포, t-분포, F-분포, Chi(카이)제곱분포...

확률적 표본추출방법
- 단순 무작위추출(Simple random sampling)
- 계통추출(Systematic sampling) : 일련번호부여 후 일정간격으로 추출
- 층화추출(Stratified sampling) : 집단을 나눈다 -> 무작위추출
- 군집추출(Cluster sampling) : 집단으로 나눈다
다중공선성(多重共線性)문제(Multicollinearity)는 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제
회귀분석의 가정조건
- 선형성 : 독립변수의 변화에 따라 종속변수도 변화하는 선형
- 독립성 : 잔차와 독립변수의 값이 관련되어 있지 않다.
- 등분산성 : 오차항들의 분포는 동일한 분산을 갖는다.
- 비상관성 : 잔차들끼리 상관이 없어야 한다.
- 정상성 : 잔차항이 정규분포를 이루어야 한다.
회귀분석결과해석
- 모형이 통계적으로 유의미한가? -> F분포값과 유의확률로 확인
- 회귀계수들이 유의미한가? -> 회귀계수의 t값과 유의확률로 확인
- 모형이 얼마나 설명력을 갖는가? -> 결정계수를 확인
- 모형이 데이터를 잘 적합하고 있는가? -> 잔차톨계량으로 확인
잔차분석
- 독립성
- 정규성
- 등분산성
회구분석 단계적 변수 선택방법
- 후진제거법(Backward Elimination)
- 전진선택법(Forward Selection)
주성분분석의 목적
- 차원축소
- 특성추출
시계열모형
- 정상성
- ARIMA(p,d,q)
AR : 자기상관함수가 지수적 감소 편자기함수 P+1WJFEKS
MA : 자기상관함수 Q+1항부터 절단, 편자기함수 지수적 감소
데이터마이닝 6가지분석
- 분류(Classification)
- 추정(Estimation)
- 예측(Prediction)
- 연관분석(Association Analysis) : 같이 팔리는 물건
- 군집(Clustering)
- 기술(Description) : 데이터의 의미를 적는다.
데이터마이닝 추진 5단계
1) 목적설정 : 마이닝을 위한 명확한 목적 설정
2) 데이터 준비 : 모델링 데이터 준비, 데이터 정제
3) 데이터 가공 : 목적변수 정의, 모델링을 위한 데이터 가공
4) 기법 적용 : 데이터마이닝 기법 적용 정보 추출
5) 검증 : 마이닝 추출결과 검증, 업무 적용, ROI(투자대비성과)
모형평가
1) ROC 그래프 : 분류 모형의 평가에 사용, x측은 (1-특이도)y축은 민감도로 나타낸다.
2) ROC 그래프는 면적이 넗을수록 좋은 모형
3) 데이터분할 : 구축용(Train), 검정용(Validation), 시험용(Test)
- 검정용 데이터는 구축된 모델의 과잉 또는 과소맞춤등에 대한 미세조정 절차를 위해 사용
교차검증(Cross Validation)
1) 홀드아웃(Hold Out)
2) K-Fold 교차검증 : 데이터 집합을 무작위로 동일 크기를 갖는 K개의 부분집합으로 나누고 그 중 1개 집합을 평가용 데이터로, 나머지를 k-1 집합을 학습데이터로 선정하여 모형을 평가하는 방법.
3) 붓스트랩
비지도학습 : 군집, 차원축소, 연관규칙, 주성분분석
아래 오분류표를 이용하여 F1-Score값을 구하시오(단, 가로:실제값, 세로:예측값) 6/19
| 예측값 TRUE | 예측값 FALSE | TOTAL | |
| 실제값 TRUE | 30(TP) | 70(FN) | 100 |
| 실제값 FALSE | 60(FP) | 40(TN) | 100 |
| TOTAL | 90 | 110 | 200 |
 |
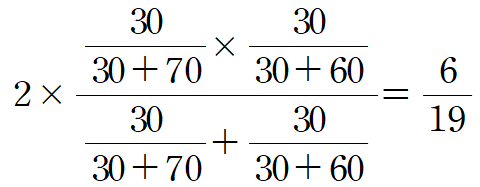 |
비지도학습 : 군집, 차원축소, 연관규칙, 주성분분석
지지도는 전체횟수가 분모
신뢰도는 우선값이 분모
| 지지도(Support) |
•전체 거래 중 항목 A와 B를 동시에 포함하는 거래의 비율
•지지도는 연관규칙 A → B, B → A가 같은 지지도를 갖기 때문에 두 규칙의 차이를 알 수가 없다. 이에 대한 평가 측 도는 무엇인가? 신뢰도
 |
| 신뢰도 (Confidence) |
•A 상품을 샀을 때 B 상품을 살 조건부 확률
 |
| 향상도 (Lift) |
•A와 B가 동시에 일어난 횟수 / A, B가 독립된 사건일 때 A, B가 동시에 일 어날 확률
•품목 A와 B 사이에 아무런 상호관계가 없으면(독립) 향상도는 1이고
•향상도가 1보다 높아질수록 연관성이 높다고 할 수 있다.
 |
지지도는 전체횟수가 분모
| > data("chickwts") > summary(chickwts) weight feed Min. :108.0 casein : 12 1st Qu. : 204.5 horsebean : 10 Median : 258.0 linseed : 12 Mean : 261.3 meatmeal : 11 3rd Qu. : 323.5 soybean : 14 Max. : 423.0 sunflower : 12 |
| 평균값(Mean) : 261.3,중앙값(Median):258.0,최빈값(Mode) Range = Max - Min (315 = 423-108) 범주형 : 서로 다른 그룹, 예시: 성별(남성, 여성), 종교(불교, 기독교, 이슬람교), 자동차 종류(세단, SUV, 트럭) 등 |
'자격증(국가,민간) > ADsP 데이터분석준전문가' 카테고리의 다른 글
| 데이터분석준전문가(ADsP) 37회 기출문제풀이 (8) | 2024.04.22 |
|---|---|
| 데이터분석준전문가(ADsP) 39회 기출문제풀이 (1) | 2024.04.22 |
| ADsP 2시간 정복 (1) | 2024.04.20 |
| 데이터분석준전문가(ADsP) 40회 기출문제풀이 (0) | 2024.04.16 |
| 데이터분석준전문가(ADsP) 38회 기출문제풀이 (0) | 2024.04.15 |



