01. 빅데이터의 가치 패러다임 변화 순서로 알맞은 것은?
1) Connction - Agency - Digitalization
2) Digitalization - Connection - Agency
3) Digitalization - Socialization - Normalization
4) Normalization - Socialization - Agency
디지털(Digitalization)-연결(Connection)-행동(Agency)
1단계: 디지털화 (Digitalization)
정의: 아날로그 정보를 디지털 정보로 변환하고 저장하는 단계입니다.
핵심 가치: 데이터 접근성 향상, 데이터 관리 효율화
대표적인 기술: 센서, 데이터베이스, 클라우드 컴퓨팅
2단계: 연결 (Connection)
정의: 분산된 데이터를 연결하고 통합하여 새로운 정보를 도출하는 단계입니다.
핵심 가치: 데이터 통합 및 분석을 통한 새로운 지식 창출
대표적인 기술: 데이터 웨어하우스, 데이터 레이크, 데이터 마이닝
3단계: 행동 (Agency)
정의: 빅데이터 분석 결과를 기반으로 의사 결정을 내리고 행동을 취하는 단계입니다.
핵심 가치: 데이터 기반 의사 결정을 통한 경쟁력 강화, 새로운 비즈니스 모델 창출
대표적인 기술: 머신 러닝, 인공지능, 예측 분석
02. 빅데이터의 출현 배경으로 알맞지 않은 것은?
1) SNS의 확산
2) 클라우드 컴퓨팅의 발전
3) 저장장치의 가격 하락
4) 중앙집중 처리의 확산
03. 빅데이터의 위기요인과 통제방안에 대한 설명으로 옳은 것은?
가. 사행활 침해의 문제는 데이터 익명화 기술로 근본적인 문제점을 차단할 수 있다.
나. 빅데이터는 일어난 일에 대한 데이터에 의존한다. 그것을 바탕으로 미래를 예측하는 것은 적지 않은 정확도를 가질 수 있지만 항상 맞을 수는 없다.
다. 데이터의 오용 피햬를 구제할 수 있는 알고리즈미스트의 역할이 증대되고 있다.
라. 범죄자들이 성향을 파악하여 사전에 범죄 예측 알고리즘을 활용하여 강력범죄를 감소시킬 수 있다.
마. 개인 사생활 침해에 대한 통제방안으로 책임제를 동의제로 전환하자는 아이디어가 대두되고 있다.
1) 가, 다
2) 나, 다
3) 나, 마
4) 가, 라
알고리즈미스트는 빅데이터 시대의 새로운 전문가로서, 데이터 분석 결과 해석 및 평가에 중점을 둡니다. 데이터 과학자나 머신 러닝 엔지니어가 수집하고 분석한 데이터를 기반으로 사업적 가치를 창출하고 윤리적 문제를 해결하는 역할을 수행합니다.
04. 데이터베이스의 일반적인 특징으로 옳지 않은 것은?
1) 데이터베이스는 다수가 공동으로 이용하는 공용 데이터이다.
2) 데이터베이스는 한 조직의 고요한 기능 수행에 필요한 운영 데이터이다.
3) 데이터베이스는 컴퓨터가 접근 가능한 저장매체에 데이터를 저장한다.
4) 데이터베이스는 한 곳에 통합된 데이터이므로 동일한 내용이더라도 중복을 허용한다.
통합된 (Intergrated) 데이터 : 동일한 내용의 데이터가 중복되어 있지 않다.
저장된(Stored) 데이터 : 컴퓨터 매체가 접근할 수 있는 저장 매체에 저장되어 있다.
공용(Shared) 데이터 : 여러 사용자가 공유할 수 있다.
변화하는(Operational) 데이터 : 삽입, 수정, 삭제를 통해 항상 최신의 정확한 데이터를 유지해야 한다.
05. 데이터 사이언티스트에게 필요한 역량에 관한 설명으로 알맞은 것은?
1) 알고리즘에 의해 부당하게 피해를 입은 인력 구제
2) 소프트 스킬로 통찰력있는 분석 수행
3) 데이터 보안을 유지하고 민감정보 및 개인정보를 보호
4) 데이터 클렌징 및 데이터 품질 검증 활동
06. 암묵지와 형식지의 상호작용에 대한 연결로 알맞은 것은?
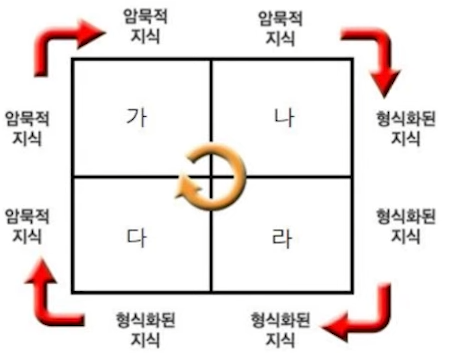
(A) 만들어진 책이나 교본을 보고 다른 직원들이 노하우를 습득하는 것
(B) 노하우를 다른 사람에게 알려주는 것
(C) 노하우를 책이나 교본 등 형식지로 만드는 것
(D) 책이나 교본에 자신이 알고 있는 새로운 지식을 추가하는 것.
1) 가-(A), 나-(B), 다-(C), 라-(D)
2) 가-(A), 나-(C), 다-(D), 라-(B)
3) 가-(C), 나-(A), 다-(D), 라-(B)
4) 가-(B), 나-(A), 다-(C), 라-(D)
- 암묵지에서 형식지로의 전환:
- 암묵적인 지식을 형식적인 지식으로 전환할 때는 주로 교육, 훈련, 문서화된 절차 등을 활용합니다. 예를 들어, 조직 내에서 중요한 경험을 갖고 있는 전문가가 그 경험을 문서화하여 교육 자료로 만들거나 훈련 프로그램을 통해 다른 직원들에게 전달할 수 있습니다.
- 형식지에서 암묵지로의 전환:
- 형식적인 지식을 암묵적인 지식으로 전환하는 데는 주로 실무 경험과 상호작용이 사용됩니다. 예를 들어, 새로운 프로젝트나 문제에 대한 해결책을 형식적인 지식인 문서화된 절차나 교육 자료에서 가져와서 직접 실험하고 경험을 통해 실제로 이해하고 체득할 수 있습니다.
- 지식 공유 및 상호작용:
- 암묵지와 형식지는 지식 공유와 상호작용을 통해 조직 내에서 지식을 전달하고 활용하는 데 중요한 역할을 합니다. 전문가나 경험 있는 직원들은 암묵적인 지식을 다른 직원들과 공유하고 형식적인 지식을 제공하여 조직적인 학습과 혁신을 촉진합니다. 이러한 지식 공유와 상호작용은 조직의 역량을 향상시키고 경쟁력을 확보하는 데 도움이 됩니다.
이렇듯 암묵지와 형식지는 지식의 생태계에서 상호보완적인 요소로 작용하여 조직 내에서 지식의 흐름을 유지하고 지식의 총량을 증진시킵니다.
| 구분 | 암묵지 | 형식지 |
| 정의 | 경험, 지식, 노하우 등의 내재화되지 않은 지식 | 문서화되고 명확하게 표현된 지식 |
| 특징 | 비구조화, 비형식화, 경험에 기반 | 구조화, 형식화, 표준화된 지식 |
| 획득 방법 | 경험, 경험 공유, 상호 작용, 체화 | 문서, 교육, 훈련, 표준 절차 |
| 처리 방법 | 경험 공유, 상호 작용, 시행착오 | 데이터 수집, 분석, 모델링, 예측 |
| 활용 | 경험 공유, 멘토링, 책임과 의지 | 의사 결정, 문제 해결, 전략 수립 |
| 예시 | 직원 간의 대화, 회의, 경험 공유 | 보고서, 프로세스 문서, 표준 운영 절차, 교육 자료 |
07. 데이터사이언티스트에 대한 설명으로 알맞지 않은 것은?
1) 데이터사이언티스트는 데이터의 다각적 분석을 통해 비즈니스의 가치를 창출해야 한다.
2) 데이터사이언티스트는 데이터 분석 중심의 개인 활동이 많아 커뮤니케이션 기술이 중요하지 않다.
3) 데이터 사이언티스트는 데이터를 이해하고 분석하는 기술뿐만 아니라 현상을 해석하는 인문학적 지식도 필요하다.
4) 데이터사이언티스트는 창의적사고, 호기심, 논리적 비판을 가지고 있는 통찰력있는 분석을 해야 한다.
08. 데이터별 가공 및 상관관계 간 이해를 통해 패턴을 인식하고 의미를 부여하는 것으로 옳은 것은?
1) 지혜
2) 지식
3) 데이터
4) 정보
DIKW
| Data(데이터) | 타 데이터와의 상관관계가 없는 가공하기 전의 순수한 수치나 기초 |
| Information(정보) | 데이터의 가공 및 상관/연관 관계 속에서 의미가 도출된 것. |
| Knowledge(지식) | 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물 |
| Wisdom(지혜) | 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 아이디어 |
09. 데이터 분석과제 관리 프로세스에 대한 설명으로 옳지 않은 것은?
1) 관리 프로세스를 통해 최종 확정된 분석과제는 과제 후보 풀(pool)로 관리한다.
2) 분석조직이 분석 과제의 기획 및 운영을 체계적으로 관리하기 위해 수립한다.
3) 분석을 수행할 팀을 구성하고 과제 수행 시 지속적인 모니터링을 수행한다.
4) 분석 조직이 지속적으로 관리 프로젝트를 수행함으로써 경쟁력을 확보할 수 있다.
10. 분석 프로젝트를 위한 영역별 관리 항목으로 알맞지 않은 것은?
1) 범위(Range)
2) 시간(Time)
3) 품질(Quality)
4) 관계(Relationship)
통합->범위->일정->원가->품질관리->의사소통->자원->리스크->이해
11. 분석 기획 단계에서 위험 대응 계획 수립 시 대응방안으로 옳지 않은 것은?
1) 완화(Mitigate)
2) 관리(Management)
3) 전이(Transfer)
4) 회피(Avoid)
빅데이터분석방법론
| 분석기획 (Planing) |
데이터 준비 (Preparing) |
데이터 분석 (Analyzing) |
시스템 구현 (Developing) |
평가 및 전개 (Deploying) |
| 비즈니스 이해 및 범위설정 |
필요 데이터 정의 | 분석용 데이터 준비 | 설계 및 구현 | 모델 발전계획 수립 |
| 프로젝트 정의 및 계획수립 |
데이터 스토어 설계 | 텍스트 분석 | 시스템 테스트 및 운영 | 프로젝트 평가 및 보고 |
| 프로젝트 위험계획 수립 |
데어터 수집 및 정확성 점검 |
탐색적 분석 | ||
| 모델링 | ||||
| 모델 평가 및 검증 | ||||
| 모델적용 및 운용방안 수립 |
12. 빅데이터 ROI 관점의 비즈니스 효과에 해당되는 것을 옳은 것은?
1) Volume
2) Velocity
3) Value
4) Variety
부피, 속도, 가치, 다양성
13. 데이터 거버넌스의 구성요소로 옳지 않은 것은?
1) 분석방법
2) 원칙
3) 조직
4) 프로세스
- 원칙(Principle) : 데이터를 유지/관리하기 위한 지침과 가이드 예)보안&품질 기준, 변경관리
- 조직(Organization) : 데이터를 관리할 조직의 역할과 책임 예)데이터관리자, DB관리자, 데이터 아키텍트
- 프로세스(Process) : 데이터 관리를 위한 활동과 체계 예) 작업절차, 모니터링 활동, 측정 활동
14. 분석 마스터 플랜 수립 시 우선순위 고려요소로 알맞지 않은 것은?
1) 전략적 중요도
2) 비즈니스 효과
3) 실행 용이성
4) 기술적용수준
15. 분석 대상이 명확하게 무엇인지 모르는 경우 기존 분석 방식을 활용하여 새로운 지식을 도출하는 분석 주체 유형은?
1) 최적화(Optimization)
2) 솔루션(Solution)
3) 발견(Discovery)
4) 통찰(Insight)
16. 빅데이터 분석 조직 구조로 옳지 않은 것은?
1) 기능구조
2) 분산구조
3) 산업구조
4) 집중구조
17. 위치 모수에 대한 설명으로 알맞지 않은 것은?
1) 평균(Mean) : 데이터의 전체 합을 전체 개수로 나누어 산출하는 대표 값이다.
2) 사분위수(Quartile) : 데이터를 작은 수부터 큰 수까지 배열했을 때 전체 관측값을 4등분하는 위치에 오는 값을n 사분위수라 한다.
3) 중위수(Median) : 데이터를 크기 순으로 나열하여 가장 중앙에 위치하는 값이다.
4) 백분위수(Percentile) : 전체 데이터에서 p번째 순위의 값을 p백분위값이라고 한다.
18. 확률변수 x가 확률질량함수 f(x)를 갖는 이산형 확률변수인 경우 그 기대값을 구하는 식으로 알맞은 것은?
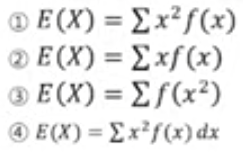
2)
19. 다음은 chickwts 데이터의 t검정 결과에 대한 해석이다. 분석 결과의 해석으로 옳지 않은 것은?
> data("chickwts")
> t_weight<-t.test(x=chickwts$weight,mu=260)
> t_weight
One Sample t-test
data: chickwts$weight
t = 0.14137, df = 70, p-value = 0.888
alternative hypothesis : true mean is not equal to 260
95 percent confidence interval:
242.8301 279.7896
sample estimates;
mean of x
261.3099
1) 전체 관측치의 개수는 70이다
2) 병아리 무게 260은 신뢰 구간안에 존재한다.
3) 병아리 무게의 95% 신뢰구간은 242.8~279.7이다
4) 병아리 무게의 점추정량은 261.3이다.
t검정(또는t-test)
샘플의 갯수 n-1 =70
df는 자유도(Degree of Freedom)mu = 모집단의 모평균
데이터:
- chickwts 데이터 세트 사용
- weight 변수: 병아리 무게 (숫자형)
- mu: 비교 기준 무게 (260g)
t 검정:
- t.test 함수 사용하여 한 표본 t 검정 수행
- 가설:
- 귀무가설 (H0): 병아리 평균 무게는 260g와 같다 (무 차이)
- 대립가설 (H1): 병아리 평균 무게는 260g와 다르다 (유의한 차이)
- 검정 결과:
- t 통계량: 0.14137
- 자유도: 70
- p 값: 0.888
- 95% 신뢰 구간: 242.8301 ~ 279.7896
- 표본 추정치:
- 평균: 261.3099g
초보자를 위한 정보 요약:
- 이 분석은 병아리 무게 데이터를 기반으로 평균 무게가 260g인지 여부를 검증합니다.
- p 값 (0.888)은 매우 높아 귀무가설 (평균 무게 260g)을 기각할 만큼 충분한 증거가 없음을 나타냅니다.
- 즉, 현재 데이터로는 병아리 평균 무게가 260g와 유의하게 다르다고 결론짓기 어렵습니다.
- 95% 신뢰 구간은 242.83g ~ 279.79g으로, 이는 실제 평균 무게가 이 범위 내에 있을 가능성이 95%임을 의미합니다.
- 이 분석 결과는 병아리 무게가 260g 기준보다 약간 높을 가능성을 시사하지만, 더 많은 데이터와 분석이 필요합니다.
주의 사항:
- 이 해석은 제한된 데이터 분석 결과를 기반으로 하며, 실제 병아리 무게에 대한 확실한 결론을 도출하기 위해서는 더 심층적인 연구가 필요합니다.
- 통계적 검정은 복잡한 과정이며, 결과 해석에는 전문적인 지식이 필요합니다.
20. 다음은 USArrests 데이터의 주성분분석 결과 R 스크립트이다. 80% 이상의 자료를 설명하려고 할 때 필요한 주성분의 최소 개소로 옳은 것은?
> fit< -princomp(USArrests,cor=TURE)
> summary(fit)
Imprttance of components;
Com.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694 0.5971291 0.41644938
Proportion of Variance 0.6200604 0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017 0.9566425 1.00000000
1) 1개
2) 2개
3) 3개
4) 4개
해설:
- summary(fit) 출력 결과에서 누적 분산 비율 항목을 확인합니다.
- 누적 분산 비율은 각 주성분이 데이터의 분산을 얼마나 설명하는지 나타냅니다.
- 80% 이상의 자료를 설명하기 위해서는 누적 분산 비율이 0.8 이상인 주성분을 선택해야 합니다.
- 본 결과에서는 첫 번째 주성분의 누적 분산 비율이 0.6200604이고, 두 번째 주성분의 누적 분산 비율을 합하면 0.8675017이 됩니다.
- 따라서 첫 번째와 두 번째 주성분만 선택하면 데이터의 80% 이상을 설명할 수 있습니다.
- 세 번째 및 네 번째 주성분은 추가적으로 선택해도 설명력 향상에 큰 도움이 되지 않을 것으로 예상됩니다.
따라서 80% 이상의 자료를 설명하기 위해 필요한 최소 주성분 개수는 2개입니다.
Standard deviation : 표준편차
Proportion of Variance ; 주성분분석
Cumulative Proportion : 누적비율
21. 목표변수(종속변수)가 연속형인 회귀나무인 분류기준값으로 알맞은 것은?
1) 카이제곱, 통계량, 지니지수
2) F-통계량, 분산감소량
3) 지니지수, 엔트로피 지수
4) 엔트로피 지수, 분산 감소량
범주형 : 카이제곱
분류형 : 통계량, 지니지수,엔트로피지수,
| 구분 | 분류형 (Classification) | 범주형 (Categorical) |
| 정의 | 입력 데이터를 기반으로 목표변수의 범주를 예측 | 입력 데이터와 목표변수가 범주 또는 카테고리 |
| 예시 | 스팸 메일 분류, 질병 진단 등 학년 (초등학생, 중학생, 고등학생), 만족도 (매우 만족, 만족, 보통, 불만족, 매우 불만족) |
성별, 직업, 국적 등 성별 (남성, 여성), 종교 (불교, 기독교, 이슬람교, 무교), 혈액형 (A형, B형, AB형, O형) |
| 순서 | 범주 간에 순서가 존재합니다. (예: 초등학생 < 중학생 < 고등학생) | 범주 간에 순서가 존재하지 않습니다. (예: 남성 = 여성, 불교 = 기독교 = 이슬람교 = 무교) |
| 종류 | 이진 분류 (Binary Classification) | 이진 변수, 다중 범주형 변수 |
| 출력 | 예측된 범주 또는 클래스 | 각 범주 또는 클래스 |
| 모델 | 분류 알고리즘 (의사결정나무, 로지스틱 회귀 등) | 범주형 변수를 사용하는 다양한 모델 |
| 평가 지표 | 정확도, 정밀도, 재현율 등 | 분할표(Confusion Matrix), 카이제곱 검정 등 |
22. 배깅(Bagging)에 대한 설명으로 옳은 것은?
1) 배깅은 반복 추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러 번 추출될 수도 있고,
어떤 데이터는 추출되지 않을 수도 있다.
2) 배깅은 다른 모델들이 각각 예측한 값을 합쳐 최종 결과를 도출해내는 방법이다.
3) 이전 모델의 학습 결과를 토대로 다음 모델에서 사용할 학습 데이터의 가중치(Weight)를 높게 조정(Update)하여 학습을 진행하는 앙상블방법이다.
4) 일반적으로 서로 다른 타입의 모델들을 사용하여 예측값을 도출한다.
앙상블모형
1) 배깅(Bagging)
- Bootstrap aggregating의 준말로 원 데이터 집합으로부터 크기가 같은 표본을 여러 번 단순 임의 복원, 추출하여 각 표본(붓스트랩 표본)에 대해 분류기 (Classifiers)를 생성한 후, 그 결과를 앙상블 하는 방법이다. 반복추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러 번 추출될 수도 있고, 어떤 데이터는 추출되지 않을 수 있다.
2) 부스팅(Boosting)
- 배깅의 과정과 유사하나 붓스트랩 표본을 구성하는 sampling 과정에서 각 자 료에 동일한 확률을 부여하는 것이 아니라, 분류가 잘못된 데이터에 더 큰 가중 치를 주어 표본을 추출한다. Adaboosting은 가장 많이 사용되는 부스팅 알고 리즘이다. 배깅과 다른 점은 분류가 잘못된 데이터에 가중치(weight)를 주어 표본을 추출한다는 점 외에는 동일하다.
3) 랜덤포레스트(Random Forest)
- 배깅(Bagging)에 랜덤 과정을 추가한 방법이다. 각 노드마다 모든 예측변수 안에서 최적의 분할을 선택하는 방법 대신 예측변수들을 임의로 추출하고, 추출된 변수 내에서 최적의 분할을 만들어 나가는 방법을 사용한다.
23. 회귀 분석에 전차의 정규성 검토에 대한 설명으로 옳지 않은 것은?
1) Q-Q Plot으로 대략적인 확인이 가능하다.
2) 잔차의 히스토그램이나 점도표를 그려서 정규성 문제를 검토하기도 한다.
3) 정규성을 검정하는 방법으로 샤피로-위크(Shapiro-Wilk), 앤더슨 달링(Anderson-Dariing) 검정 등을 이용할 수 있다.
4) 정규성을 만족하지 않을 때는 종속변수와 상관계수가 높은 독립변수를 제거한다.
Q-Q plot은 "Quantile-Quantile plot"의 줄임말로, "분위수(Quantile);데이터의 분포에서 전체 넓이를 일정 비로 나누어 위치에 있는 갓ㅂ"두 확률 분포의 분위수를 비교하여 그린 그래프입니다. 주어진 데이터 집합이 정규 분포와 같은 특정 분포를 따르는지 확인하는 데 사용됩니다. 일반적으로 정규 분포를 가정하고, 데이터의 분위수를 정규 분포의 분위수와 비교하여 데이터가 정규 분포를 따르는지 시각적으로 확인할 수 있습니다.
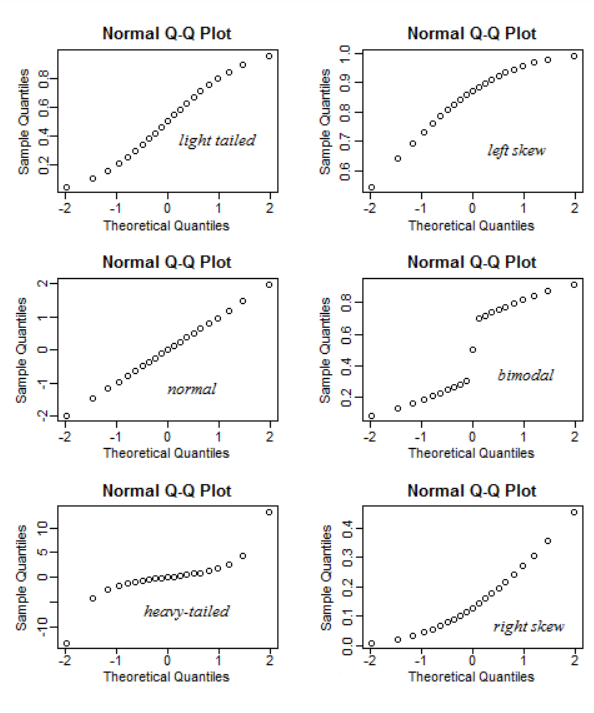
24. 분해 시계열을 구성하는 요인으로 옳지 않은 것은?
1) 추세요인(Trend Factor)
2) 순환요인(Cycle Factor)
3) 계절요인(Season Factor)
4) 정상요인(Normalcy Factor)
분해시계열
- 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
1) 추세요인 (Trend Factor) : 자료가 어떤 특정한 형태를 취할 때
2) 계절요인 (Seasonal Factor) : 계절에 따라 고정된 주기에 따라 자료가 변화할 경우
3) 순환요인 (Cyclical factor) : 알려지지 않은 주기를 가지고 자료가 변화할 때
4) 불규칙요인 (Irregular factor) : 위 세가지 요인으로 설명할 수 없는 회귀분석에서오차에 해당하는 요인
25. 도출된 연관 규칙이 얼마나 유의성이 있는지 확인하기 위한 측정지표로 옳지 않은 것은?
1) 지지도(Support)
2) 신뢰도(Confidence)
3) 향상도(Lift)
4) 순수도(Purity)
순수도 : 의사결정나무의 불순도 기준
(지니지수의 값이 클수록 이질적(Diversity)이며 순수도(Purity)가 낮다고 볼 수 있다.
엔트로피지수의 값이 클수록 순수도(Purity)가 낮다고 볼 수 있다.
26. 다음 두 좌표 a,b의 유클리드 거리로 옳은 것은?
a(185,70),b(180,75)


유클리드거리 (Euclidean) : 두 점간 차를 제곱하여 모두 더한 값의 양 의 제곱근
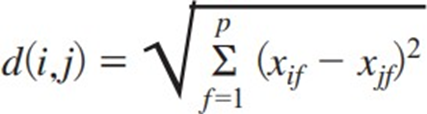
맨해튼거리 (Manhattan) : 두 점 간 차의 절댓값을 합한 값
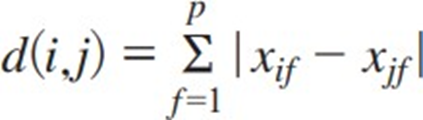
맨해튼거리 : |185-180| + |70-75| = 5+5 = 10
27. 빅데이터의 활용 기법 중 우유 구매자가 기저귀를 같이 구매할 경우를 분석하는 방법으로 적합한 것은?
1) 유형분석
2) 유전 알고리즘
3) 머신러닝(기계학습)
4) 연관규칙
28. 오분류표의 특이도(Specificity)를 구하는 공식으로 옳은 것은? 1)

| 오분류표 | 예측값 | ||
| TRUE | FALSE | ||
| 실제값 | TRUE | 15(TP) | 60(FN) |
| FALSE | 60(FP) | 30(TN) | |
1/5
F1 Score는 일반적으로 정밀도(Precision)와 재현율(Recall)을 사용하여 계산하지만, 오분류표(Confusion Matrix)를 사용하여 계산하는 방법도 있습니다.
오분류표를 이용한 F1 Score 계산 공식:
F1 Score = 2 *(정확도*재현율)/(정확도+재현율)
정확도(Precision)=TP / TP + FP=15/75=1/5
재현율(Recall)=TP / TP + FN=15/75=1/5
특이도(Specifity)=TN / TN + FP=30/60+30=1/3
F1 Score = 2 * (TP / (TP + FP)) * (TP / (TP + FN)) / ((TP / (TP + FP)) + (TP / (TP + FN)))
2*(0.2*0.2/0.2+0.2)=1/5
29. 군집분석에 대한 설명으로 적절하지 않은 것은?
1) 군집분석 결과에 대한 타당성과 안정성에 대한 검정으로 교차타당성을 이용할 수 있다.
2) 군집분석은 비지도학습(Unsupervised Learining)이다.
3) 계층적 군집분석은 덴드로그램(Dendrogram)을 활용하여 시각화 할 수 있다.
4) 군집분석은 군집 간의 이질성과 군집 내의 동질성이 모두 낮아지는 방향으로 군집을 만든다.
4) 군집분석은 군집 간의 이질성과 군집 내의 동질성이 모두 높아지는 방향으로 군집을 만든다.
30. 표본조사에 대한 설명으로 옳지 않은 것은?
1) 조사과정에서 발생하는 오류는 표본추출 오류와 비표본추출 오류로 분류할 수 있다.
2) 표본편의(Sampling Bias)는 표본추출방법에서 기인하는 오차를 의미한다.
3) 표본편의는 정규화(Normalization)를 통해 최소화하거나 없앨 수 있다.
4) 표본오차는 표본크기가 증가함에 따라 모집단을 더 정확히 반영하게 되어 감소한다.
확률 : 계층분석, 군집분석
비확률
31. 주성분분석에 대한 설명 중 옳지 않은 것은?
1) 주성분분석은 고차원의 데이터를 선형 연관성이 없는 저차원의 데이터로 차원을 축소한다.
2) 주성분분석은 지도학습(Supervised Learning)에 속하는 알고리즘이다.
3) 공분산행렬은 변수의 측정 단위를 그대로를 반영한 것이고 상관행렬은 모든 변수의 측정단위를 표준화한 것이다.
4) 공분산행렬을 이용한 분석의 경우 변수들의 측정 단위에 민감하다.
비지도학습 : 군집, 차원축소, 연관규칙, 주성분분석
32. 아래는 자동차 속도와 제동거리 등에 대한 데이터의 분석결과이다. 다음 중 유의수준 0.05에서 이에 대한 설명으로 가장 옳지 않은 것은?(speed:속도, dist:제동거리)
> lm_model = lm(dist ~ speed, data = cars)
> summary(Im_model)
Call:
lm(formula = dist ~ speed, data = cars)
Residuals:
Min 1Q Median 3Q Max
-29.069 -9.525 -2.272 9.215 43.201
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5791 6.7584 -2.601 0.0123 *
Time 3.9324 0.4155 9.464 1.49e-12 ***
---
Signif. codes: 0 '***' 0.001 '***' 0.01 '*' 0.05 ',' 0.1 ' ' 1
Residual standard error: 15.38 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
1) speed가 상승할 수록 dist가 올라가는 경향이 있다.
2) dist의 분산을 speed가 약 64% 설명해주고 있다.
3) 위의 회귀식은 유의수준 0.05에서 dist의 변동성을 설명하는데 유의하다.
4) 독립변수인 speed와 종속변수인 dist는 강한 상관관계를 가지고 있다.
lm : 선형회귀분석
- 모델: dist(거리)를 speed(속도)로 예측하는 회귀 모델
- Residuals(잔차): 예측값과 실제 값 간의 차이를 나타내는 값들의 분포에 대한 요약 통계
- Coefficients(계수): 회귀 모델의 계수(절편과 기울기)에 대한 추정치와 통계적 유의성에 대한 정보
- Residual standard error(잔차 표준 오차): 모델이 예측하는 값과 실제 값 간의 평균적인 편차
- Multiple R-squared(다중 결정 계수): 모델이 데이터를 얼마나 잘 설명하는지를 나타내는 지표. 이 모델에서는 0.6511로, 속도(speed)가 거리(dist)를 약 65.11% 정도로 설명한다고 해석할 수 있습니다.
- Adjusted R-squared(조정된 다중 결정 계수): 다중 결정 계수를 데이터의 복잡성에 대한 조정을 통해 수정한 값. 이 모델에서는 0.6438로, 조정된 결정 계수는 다중 회귀 모델에서 사용되는 보다 정확한 지표입니다.
- F-statistic: 회귀 모델의 적합도를 검정하기 위한 F-통계량 값
- p-value: F-통계량의 유의성에 대한 확률 값. 매우 작은 값(여기서는 1.49e-12)으로, 모델이 통계적으로 유의하다는 것을 나타냅니다.
분석 내용:
- 이 모델은 속도(speed)를 독립 변수로 사용하여 거리(dist)를 예측하는 회귀 모델입니다.
- 회귀 계수에 대한 해석: 속도(speed)가 거리(dist)에 대해 양의 관계를 보입니다. 즉, 속도가 증가할수록 거리도 증가하는 경향을 보입니다.
- 다중 결정 계수(Multiple R-squared)가 0.6511로 측정되었으며, 이는 모델이 데이터의 약 65.11%를 설명한다는 것을 나타냅니다.
- F-통계량의 p-value가 매우 작으므로 이 모델은 통계적으로 유의합니다.
33. 다음 중 나이, 신분, 수입 기준으로 월평균 신용카드 사용금액에 대한 분석을 할 때 적합한 분석 모형은?
1) 능형회귀(Ridge Regreesion)
2) 단순회귀(Simple Regreesion)
3) 다중회귀(Multiple Regreesion)
4) 로지스틱회귀(Logistic Regreesion)
릿지 회귀(Ridge regression)는 독립 변수의 상관 관계가 높은 시나리오에서 다중 회귀 모델의 계수를 추정하는 방법이다. 계량경제학, 화학, 공학 등 다양한 분야에서 사용
34. 다음의 다중 로지스틱 회귀분석 결과에 대한 설명으로 옳지 않은 것은?
#default(채무 불이행 여부, yes/no)
#studentsYes(학생 여부, yes/no)
#balance(채무잔액)
#income(연수입)
> model<-glm(default ~ ., data=Default, famiy=binomial)
> summary(model)
Call:
glm(formula = default ~ , family = binomial, data = Default)
Diviance Residuals:
Min 1Q Median 3Q Max
-2.4691 -0.1418 -0.0557 -0.0203 3.7383
Coefficients:
Estimate Std. Error z value Pr(>|t|)
(Intercept) -1.087e+01 4.923e-01 -22.080 < 2e-16 ***
studentYes -6.468e-01 2.363e-01 -2.738 0.00619 **
balance 5.737e-03 2.319e-04 24.738 < 2e-16 ***
income 3.033e-06 8.203e-06 0.370 0.71152
---
Signif. codes: 0 '***' 0.001 '***' 0.01 '*' 0.05 ',' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance : 2920.6 on 9999 degrees of freedom
Residual deviance : 1571.5 on 9996 degrees of freedom
AIC : 1579.5
Number of Fisher Scoring iteration : 8
1) studentYes 일 때 채무불이행(default)될 확률이 적다.
2) 로지스틱 회귀분석은 지도학습에 해당된다.
3) income은 default에 통계적으로 유의미한 영향을 주는 변수이다.
4) balance는 default(연체여부)에 통계적으로 유의미한 영향을 주는 변수이다.
주어진 결과는 이항 로지스틱 회귀 모델의 요약 정보를 제공합니다. 이를 해석해보겠습니다.
- 회귀 모델의 요약 정보:
- 모델: 채무 불이행 여부(default)를 다른 변수들을 통해 예측하는 이항 로지스틱 회귀 모델
- Deviance Residuals(편차 잔차): 모델의 적합도를 나타내는 지표. 작을수록 모델이 데이터를 잘 설명한다는 것을 의미합니다.
- Coefficients(계수): 회귀 모델의 계수(절편과 기울기)에 대한 추정치와 통계적 유의성에 대한 정보
- Null deviance와 Residual deviance: 모델의 적합도를 검정하는 지표. Null deviance는 절편만 있는 모델의 편차를 나타내고, Residual deviance는 실제 모델의 편차를 나타냅니다.
- AIC(Akaike Information Criterion): 모델들 간의 비교를 위한 정보 기준. 값이 작을수록 모델이 더 좋은 적합도를 보입니다.
- 분석 내용:
- 이 모델은 채무 불이행 여부(default)를 예측하기 위해 학생 여부(studentYes), 채무잔액(balance), 연수입(income)을 독립 변수로 사용하는 이항 로지스틱 회귀 모델입니다.
- 회귀 계수에 대한 해석:
- 학생 여부(studentYes) 변수의 회귀 계수는 -0.6478이며, 이 값은 통계적으로 유의합니다. 즉, 학생일 경우 채무 불이행 가능성이 낮아진다는 것을 의미합니다.
- 채무잔액(balance) 변수의 회귀 계수는 0.0057이며, 이 값은 매우 통계적으로 유의합니다. 따라서 채무잔액이 증가할수록 채무 불이행 가능성이 높아집니다.
- 연수입(income) 변수의 회귀 계수는 0.000003033이며, 이 값은 통계적으로 유의하지 않습니다. 따라서 연수입과 채무 불이행 여부 간의 관계는 통계적으로 유의하지 않은 것으로 나타납니다.
- 모델의 적합도:
- Null deviance와 Residual deviance를 비교하여 모델의 적합도를 평가할 수 있습니다. Residual deviance가 Null deviance에 비해 작으므로, 이 모델은 주어진 데이터를 상당히 잘 설명한다고 할 수 있습니다.
- AIC 값은 1579.5로, 다른 모델들과 비교했을 때 상대적으로 적은 정보 손실을 보입니다. 따라서 이 모델은 다른 모델들보다 더 좋은 적합도를 보입니다.
이러한 분석을 통해 채무 불이행 여부를 예측하는 데에 학생 여부와 채무잔액이 중요한 변수임을 확인할 수 있습니다.
35. 다음 중 자기조직화지도(SOM)방법에 대한 설명으로 옳지 않은 것은?
1) SOM은 입력변수의 위치 관계를 그대로 보존한다는 특징으로 인해 입력 변수의 정보와 그들의 관계가 지도상에 그대로 나타난다.
2) SOM은 경재 학습으로 각각의 뉴런이 입력 벡터와 얼마나 가까운 가를 계산하여 연결강도를 반복적으로 재조정하여 학습한다.
3) SOM 알고리즘은 고차원의 데이터를 저차원의 지도형태로 형상화하기 때문에 시각적으로 이해하기 쉽다.
4) SOM을 이용한 군집분석은 인공신경망의 역전파 알고리즘을 사용함으로써 수행 속도가 빠르고 군집의 성능이 매우 우수하다.
자기조직화지도, 또는 자기조직화맵(SOM, Self-Organizing Map)은 인공지능 분야에서 사용되는 비지도 학습 기법 중 하나입니다.
- 고차원 데이터를 저차원 공간으로 시각화하는 데 도움이 됩니다.
- 데이터 간의 유사도를 보존하면서 데이터를 군집화하는 데 사용됩니다.
36. 앞면이 나올 확률이 0.5인 동전 3개를 던졌을 때 앞면이 한 번만 나올 확률은?
1) 3/5
2) 3/7
3) 2/8
4) 3/8
베르누이분포 이항확률
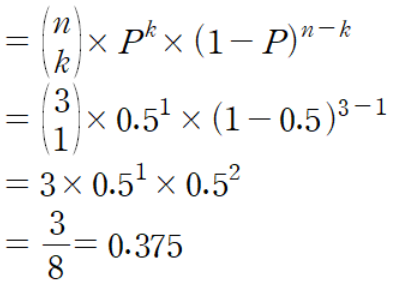
앞면이 나올 확률이 0.5인 동전 3개를 던졌을 때 앞면이 한 번만 나올 확률을 계산하려면 이항 확률 공식을 사용할 수 있습니다.
이항 확률 공식은 다음과 같습니다.
P(X=k)=(nk)×pk×(1−p)n−kP(X = k) = \binom{n}{k} \times p^k \times (1 - p)^{n - k}P(X=k)=(kn)×pk×(1−p)n−k
어디:
- P(X=k)P(X = k)P(X=k)는 정확히 kkk개의 성공을 얻을 확률입니다.
- nnn은 시행 횟수(이 경우 동전 던지기 횟수)입니다.
- kkk는 우리가 관심을 갖는 성공 횟수입니다(이 경우 앞면은 한 번만 얻음).
- ppp는 각 시행의 성공 확률입니다(이 경우 앞면이 나올 확률은 0.5입니다).
- (1−p)(1 - p)(1−p)는 각 시행의 실패 확률입니다(이 경우 뒷면이 나올 확률은 0.5입니다).
이 공식을 사용하여 다음 값을 연결할 수 있습니다.
- n=3n = 3n=3 (동전 3개를 던지기 때문입니다).
- k=1k = 1k=1 (앞면이 한 번만 나오길 원하기 때문에)
- p=0.5p = 0.5p=0.5 (앞면이 나올 확률)
P(X=1)=(31)×(0.5)1×(1−0.5)3−1P(X = 1) = \binom{3}{1} \times (0.5)^1 \ \times (1 - 0.5)^{3 - 1}P(X=1)=(13)×(0.5)1×(1−0.5)3−1
이제 공식의 각 부분을 계산해 보겠습니다.
- (31)\binom{3}{1}(13)은 3번의 시도 중 1번의 성공을 선택하는 방법의 수입니다. 즉, (31)=3!1!(3−1)!=입니다. 3\binom{3}{1} = \frac{3!}{1!(3-1)!} = 3(13)=1!(3−1)!3!=3 .
- (0.5)1(0.5)^1(0.5)1은 앞면이 한 번 나올 확률입니다.
- (1−0.5)3−1(1 - 0.5)^{3 - 1}(1−0.5)3−1은 뒷면이 두 번 나올 확률입니다.
P(X=1)=3×(0.5)1×(0.5)2P(X = 1) = 3 \times (0.5)^1 \times (0.5)^{2}P(X= 1)=3×(0.5)1×(0.5)2
P(X=1)=3×0.5×0.25P(X = 1) = 3 \times 0.5 \times 0.25P(X=1)=3×0.5×0.25
P(X=1)=0.375P(X = 1) = 0.375P(X=1)=0.375
따라서 앞면이 나올 확률 0.5로 동전 3개를 던졌을 때 앞면이 한 번만 나올 확률은 0.375입니다.
37. ARIMA(자기회귀 누적 이동평균 모형)는 기본적으로 비정상 시계열 모형이기 때문에 차분이아 변환을 통해 AR, MA, ARMA 모형으로 정상화할 수 있다. ARIMA(1,2,3)에서 ARMA로 정상화할 때, 차분한 횟수로 옳은 것은?
1) 1
2) 2
3) 3
4) 4
AR + I + MA
1 2 3
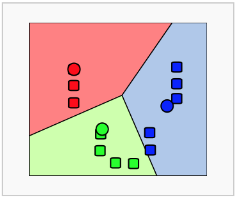
38. 비계층적 군집분석인 K-means 군집분석의 수행 순서로 옳은 것은?
가) 초기 군집의 중심으로 k개의 객체를 임의로 선택한다.
나) 각 자료를 가장 가까운 군집 중심에 할당한다.
다) 각 군집 내의 자료들의 평균을 계산하여 군집의 중심을 갱신한다.
라) 군집 중심의 변화가 거의 없을 때까지 단계2와 단계3을 반복한다.
1) 나->가->다->라
2) 다->나->가->라
3) 가->나->다->라
4) 라->가->나->다
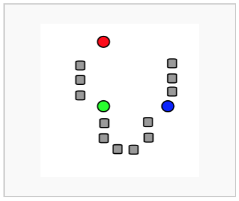 |
1. 초기점(k) 설정
|
 |
2. 그룹(cluster) 부여
|
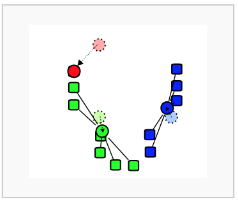 |
3. 중심점(centroid) 업데이트
|
 |
4. 최적화
|
39. 다음 중 K-폴드 교차검증에 대한 설명으로 적절하지 않은 것은?
1) K=2인 경우 LOOCV(Leave-One-Out-Cross Validation)이라고 한다.
2) 교차검증은 주어진 데이터를 가지고 반복적으로 성과를 측정하여 그 결과를 평균한 것으로 분류분석 모형을 평가하는 방법이다.
3) 대표적인 k-fold 교차검증은 일반적으로 10-fold 교차검증이 사용된다.
4) 교차검증을 하는 이뉴는 과적합을 피하고 일반화된 모델을 모델을 생성하기 위함이다.
k-fold cross-validation(k-겹 교차 검증)은 가장 널리 사용되는 교차 검증 방법의 하나로, 데이터를 k개로 분할한 뒤, k-1개를 학습용 데이터 세트로, 1개를 평가용 데이터 세트로 사용하는데, 이 방법을 k번 반복하여 k개의 성능 지표를 얻어내는 방법
K-Fold Cross-Validation
- 전체 데이터 셋을 k개의 그룹으로 분할하여 한 그룹은 validation set, 나머지 그룹은 train set으로 사용합니다.
- k번 fit을 진행하여 k개의 MSE를 평균내어 최종 MSE를 계산합니다.
- LOOCV보다 연산량이 낮습니다.
- 중간 정도의 bias와 variance를 갖습니다.

2. LOOCV(Leave-One-Out Cross-Validation)
- 단 하나의 관측값(x1, y1)만을 validation set으로 사용하고, 나머지 n-1개 관측값은 train set으로 사용합니다.
- n번 fitting을 진행하고, n개의 MSE를 평균하여 최종 MSE를 계산합니다.
- n-1개 관측값을 train에 사용하므로 bias가 낮습니다.
- overfitting 되어 높은 variance를 갖습니다.
- n번 나누고 n번 fit 하므로 랜덤성이 없습니다.
- n번 fit을 진행하므로 expensive 합니다.
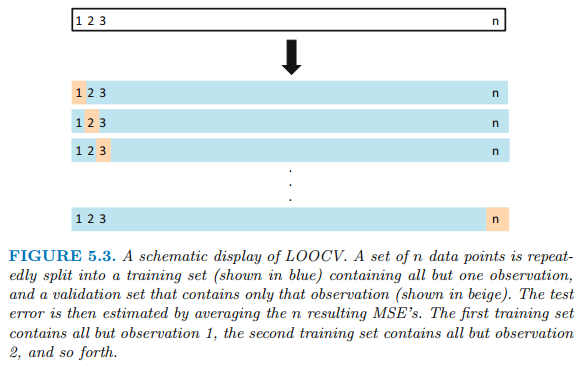
40. 시게열 분석에 관한 설명으로 옳지 않은 것은?
1) AR모형은 과거의 값이 현재의 값에 영향을 줄 때 사용하며, MA모형은 오차를 이용해 회귀식을 만드는 방법이다.
2) ARMA모형은 약산 정상성을 가진 확률적 시계열을 표현하는데 사용한다.
3) 지수평활법은 특정 기간 안에 속하는 시계열에 대해서는 동일한 가중치를 부여한다.
4) 대부분의 시계열은 비정상 자료이다. 그러므로, 비정상 자료를 정상성 조건에 만족시켜 정싱시계열로 만든 후 시계열 분석을 한다.
지수 평활법은 최근의 자료에 더 큰 가중치를 주고 현 시점에서 멀수록 작은 가중치를 주어 지수적으로 과거의 비중을 줄여 미래값을 예측하는 방법
41. 아래 빈칸에 알맞은 용어는?
(ㄱ)는 원인과 결과의 관계, (ㄴ)는 관련성이 있는 관게를 뜻하며 빅데이터 시대에는(ㄱ)보다(ㄴ)가 중요시 되고 있다.
인과, 관계
42. 아래 빈칸에 알맞은 용어는?
( )은 기업이 고객별 구매 이력 데이터베이스를 분석, 활용하여 고객에 대한 이해를 돕고 고객 대상의 각종 마케팅 전략으로 활용하는 것을 의미한다.
CRM
43. 다음 설명에 적합한 개발 모델은?
[반복을 통해 점진적으로 개발하는 방법으로 검증 또는 처음 시작하는 프로젝트에는 적용이 쉽지만 관리 체계를 갖추지 못한 경우 복잡도가 상승하여 프로젝트 진행이 어려울 수 있다.]
나선형
44. 빈 칸에 알맞은 접근 방식은?
( )은 문제를 정의하기 어려워 문제를 지속적으로 개선해 나가는 접근법이다. ( )을 통해 통찰과 지식을 얻을 수 있다.
상향식 접근법
45. 아래 빈칸에 알맞은 용어는?
exp( )의 의미는 x1, x2, ....., xk가 주어질 때, x1이 한 단위 증가할 때 마다 성공(y=1)의 ( )가 몇 배 증가하는 지를 나타내는 값이다.
오즈
46. 표본의 정보로부터 모집단의 모수를 하나의 값으로 추정하는 것은 무엇인가?
점추정
47. 아래 거래 데이터에서 콜라->맥주의 지지도는? 3/6
| 거래번호 | 판매상품 |
| 1 | 소주, 콜라, 맥주 |
| 2 | 소주, 콜라, 와인 |
| 3 | 소주, 주스 |
| 4 | 콜라, 맥주 |
| 5 | 소주, 콜라, 맥주, 와인 |
| 6 | 주스 |

| 지지도(Support) |
•전체 거래 중 항목 A와 B를 동시에 포함하는 거래의 비율
•지지도는 연관규칙 A → B, B → A가 같은 지지도를 갖기 때문에 두 규칙의 차이를 알 수가 없다. 이에 대한 평가 측 도는 무엇인가? 신뢰도
 |
| 신뢰도 (Confidence) |
•A 상품을 샀을 때 B 상품을 살 조건부 확률
 |
| 향상도 (Lift) |
•A와 B가 동시에 일어난 횟수 / A, B가 독립된 사건일 때 A, B가 동시에 일 어날 확률
•품목 A와 B 사이에 아무런 상호관계가 없으면(독립) 향상도는 1이고
•향상도가 1보다 높아질수록 연관성이 높다고 할 수 있다.
 |
지지도는 전체횟수가 분모
신뢰도는 우선값이 분모
48. P(A)=0.3, P(B)=0.4이다. 두 사건 A와 B가 독립일 경우 P(B|A)는?
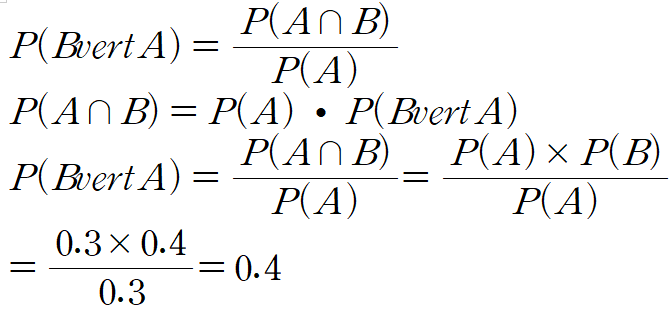
0.4
49. 아래에서 설명하는 표본추출 방법은?
[모집단의 추출틀에서 n번째 간격마다 하나씩 표본으로 추출하는 방법이다.
(표본의 크기 n : 전체 모집단의 크기가 N인 경우에 n=N/k)
계통표본추출
50. 여러 대상 간의 거리가 주어졌을 때, 대상들을 동일한 상대적 거리를가진 실수공간의 점들로 배치시키는 차원 축소 방법은?
다차원척도법(MDS)
ADsP 39회 기출 -1
https://youtu.be/1hFg0PmPpJM?si=IilgWiYajzaiZWtW
ADsP 39회 기출 -2
https://youtu.be/INm6JQ2zbpM?si=YiwyQuKrOF1UzSfR
ADsP 39회 기출 -3
https://youtu.be/sEoWoobiwJ0?si=OaFu_d_b0HuMlxiE
https://www.dataq.or.kr/www/accept/schedule.do
데이터자격시험
데이터아키텍처 준전문가 제56회 - 2.12~16 2.29 3.16(토) 4.5~9 4.12 -
www.dataq.or.kr
'자격증(국가,민간) > ADsP 데이터분석준전문가' 카테고리의 다른 글
| 데이터분석준전문가(ADsP) 35회 기출변형문제풀이 (1) | 2024.04.23 |
|---|---|
| 데이터분석준전문가(ADsP) 37회 기출문제풀이 (8) | 2024.04.22 |
| ADsP데이터분석준전문가 2024 나름내용정리 (0) | 2024.04.21 |
| ADsP 2시간 정복 (1) | 2024.04.20 |
| 데이터분석준전문가(ADsP) 40회 기출문제풀이 (0) | 2024.04.16 |



